Docker镜像最佳实践
Docker 镜像最佳实践
5 条最佳建议
1.仅安装产线需要依赖与软件
镜像尽可能最小原则
- 仅复制 jar/war
- 使用自定义 JRE(Java Runtime Environment)
2.使用多阶段构建
1 | FROM maven:3.6.3-jdk-11-slim AS build |
镜像尽可能最小原则
1 | FROM maven:3.6.3-jdk-11-slim AS build |
杜架的技术月刊,主要关注计算机领域,记录本月看到的有价值的信息,主要包含:碎片化思考,阅读笔记分享,开源项目(软件)介绍。内容主题可能有极大的个人喜好偏向,努力做个输出的人,爱我所爱,想我所想,写我所写。

岁月无痕,流光难驻。用笔印证心灵的虹影,用心感悟时代的呼声,让过往的岁月留存,让看过的世界被更多的人知晓,爱我所爱,想我所想,写我所写,这便是创刊的情和志。
学习任何事务首先要学会基本的规则,然后才能知道什么时候去打破规则。这个原则放在很多地方都能适用。
例如:如何成为一个厉害的程序员,刚入行,大佬会告诉你先按这样写,而这样就是规则,新人最容易创新,但也最容易出错,往往忽略规则,忽略约定成俗,你的视野决定了你看问题的高度,当你掌握基本规则,那么我相信你的很多新奇的想法就可以实现了。为什么大佬告诉你程序员要懂设计原则和设计模式,我想这个应该算是程序员世界的规则吧。
人类孜孜不倦的探索着世界的本质,或者说一个物体的本质,原子核,质子,电子,夸克,这些都可以用数学公式来解释,人的认知能力是有限的,想象力也只局限于三维世界,这些都可以用数学来描述,数学可以让我们看的更远,看到一些我们无法想象的事。三个苹果+两个苹果等于五个苹果,三个桃+两个桃等于五个桃子,抛开外在干扰,3+2=5,这个是本质。外在因素再变化,这个数学本质没有变化,所以我想说未来对世界的探索可能还会有新的发展,新的变化,但数学一定是永恒的。
一份团队工程经验(新人指导)可以极大的提升团队协作能力,代码质量,生产效率等等方面,而不是手把手教每一个新人。这个其实是做事的第一个阶段,经验文档化,方案演进化。整理了一个思维图: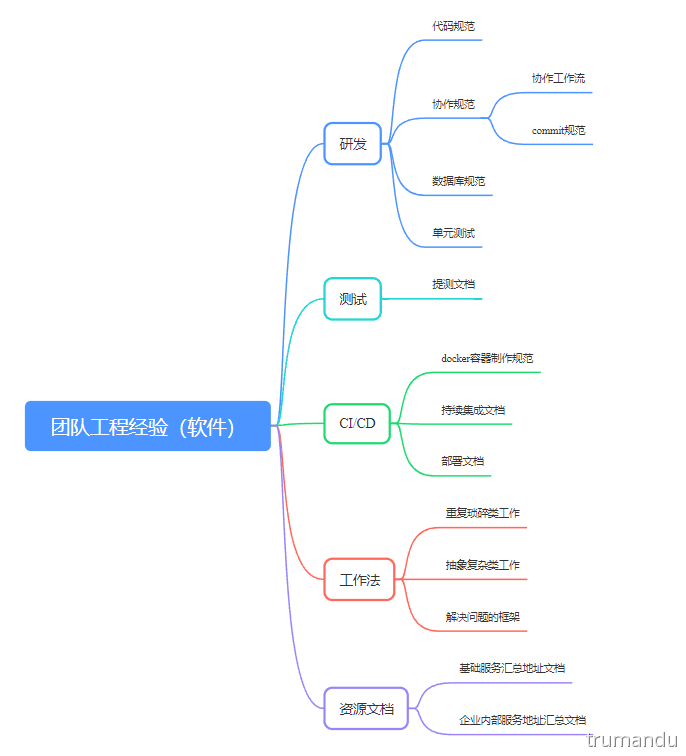

大家好,很荣幸收到西安 GDG社区的邀请,来做一场有关kafka的分享。
我今天分享的话题是《kafka那些事》,主要内容是关于kafka技术入门分享,说说它的生态,讲讲自己的生产实践经验。
在正式开始之前,我想了解一下大家做后端的都有哪些?请举手。前端呢?

在开始之前,先做个简单的自我介绍,我是truman,目前是Newegg架构师,同时也是西安IT技术圈社区发起人,主要关注于软件架构,中间件平台类开发,大数据基础架构等相关工作。
这里有我的公众号和我们社区的公众号,感兴趣的可以关注一波。
自己也开源了一些项目,做的比较好的有vs code 插件43k下载,给kibana贡献过代码,自己开源的kafka平台KafkaCenter在github上也有1k星。
总结一下:是一个喜欢开源,热爱分享,希望多和大家交流学习。
在开始之前,我想问你一个问题:你有复盘的习惯吗?
我先回答这个问题,我几乎很少复盘,偶尔只是回顾,不是那种详细的回顾,而是偶然性懊悔和反思。就像写这篇文章一样,但不是复盘。我所以理解的复盘是一个做事的习惯,不仅是工作上,生活上同样是可以复盘的,工作中的经验同样可以在生活中发挥作用的,反哺生活。
今天的分享动力来源于最近看到一篇文章,推荐研读:一个程序员的成长之路

正好就趁此审视自己,规划自己未来的路。
Side Project 中文名是副业,业余项目,边际项目的意思。很多成功的项目都是由此发展而成的,像简书,VUE, Elasticsearch等。
Side Project 对于程序员也许是我们成功或者成长的一条路之一。
做一个Side Project会有很多收益:
如果你像我一样会有一丝丝的焦虑,那么希望你可以考虑一下Side Project,尝试自己做自己的老板,即使失败,对于你的职业生涯,也会有一些帮助,
会让你更多的考虑技术背后的业务逻辑。
公司依靠软件系统提供业务服务而创造价值,程序员则是通过构建并持续演进软件系统服务能力以及业务功能以支撑公司业务发展从而创造价值。
软件系统的价值是以解决业务问题的能力、支撑业务增长的能力为衡量标准。
从价值出发-找寻学习与工作的新思路
今晚偶然看到【竹白】,好奇心驱使下,研究了一下,使用和产品风格一样,简单,留白,挺有意思的。
不知道自己在这个平台会停留多久,暂且用这篇碎碎念完成首篇。
最近脑海里一直有几个疑问:
好的程序员是什么样的?
如何保持自己的学习力和竞争力?
作为程序员,自己未来的路怎么走?
总的来说满满的焦虑,我也不知道为什么会是这样,也许工作久了的职场人都会有这样的担忧吧,当然家庭富裕和躺平的除外。
看待任何事物,从多个不同的角度看问题,就像程序设计一样,多列几个架构方案,总会让你有意外的收获。
最近看了一篇文章,我觉得写的很好。和好多年前在学校图书馆看到的一本书上,写的不同待遇的秘书做事风格,分析问题的角度很相似。
程序员的日常工作通常分为两种:重复琐碎类工作和抽象复杂类工作。
重复琐碎类工作的不同做法:
第一种:就事论事,把这个问题回答了结束。到这个程度你只是解决了一个具体的问题。很可惜我们很多技术同学都是处于这个层次。
第二种:解答完这个问题后即整理成文档,把排查步骤写清楚,提升自己和同组人的工作效率。到这个程度说明你看到并解决了内部效率问题。
第三种:将此排查问题的方法和逻辑固化为小工具给到咨询的同学去用,让他以后可以自助排查解决,这样既解决了别人的问题也彻底释放了自己和同组人的效能。到这个程度说明你重新定义了效能问题并找到更好提效的办法。
第四种:将此问题背后根因找到,从业务原理或者产品功能上去找解法。将技术工具抽象为业务功能的完善。到这个程度说明你已经从单纯的技术提效看到了架构合理性问题,并尝试在业务上寻求彻底根治的办法。
抽象复杂类工作的不同做法
第一种:找到抱怨的同学,问一问具体的问题是什么,然后针对性解决。
第二种:更加广泛收集问题,然后列出来表格,归类分析并安排负责人跟进解决,最后定期跟踪进度。
第三种:深入分析表格的中的问题并对问题进行抽象,从架构调优和产品功能的角度去寻找原因,并寻找解决这些问题带来的业务价值,并确定目标拆解路径,最后按照任务推进和跟踪进展。
第四种:从更全局角度去思考此目标与年度目标的关系,与组织发展的关系,思考如何扩大此事的效益,思考如何通过这些事的解决锻炼和培养团队同学。
原文连接:关于技术能力的思考和总结
1 | create database if not exists db_hive; |
1 | show tables; |
创建表
1 | CREATE TABLE if not exists db_hive.db_table( |
创建临时表
1 | create temporary table tmp_fact_sale as |
查看表详情
1 | desc db_table; |
查看表创建语句
1 | show create table table1; |
删除表
1 | drop table db_hive.db_table; |
分区表
1 | CREATE TABLE if not exists db_hive.db_table( |
技术能力本质就是解决问题的能力,在编程领域,就是对遇到的业务问题进行抽象、提炼以及逻辑的构建,通过研发工具以提升解决问题的效能,减低人工低效的重复工作。
以写代想,以想促讲,以讲验真
重复琐碎类工作的不同做法:
第一种:就事论事,把这个问题回答了结束。到这个程度你只是解决了一个具体的问题。很可惜我们很多技术同学都是处于这个层次。
第二种:解答完这个问题后即整理成文档,把排查步骤写清楚,提升自己和同组人的工作效率。到这个程度说明你看到并解决了内部效率问题。
第三种:将此排查问题的方法和逻辑固化为小工具给到咨询的同学去用,让他以后可以自助排查解决,这样既解决了别人的问题也彻底释放了自己和同组人的效能。到这个程度说明你重新定义了效能问题并找到更好提效的办法。
第四种:将此问题背后根因找到,从业务原理或者产品功能上去找解法。将技术工具抽象为业务功能的完善。到这个程度说明你已经从单纯的技术提效看到了架构合理性问题,并尝试在业务上寻求彻底根治的办法。
抽象复杂类工作的不同做法
第一种:找到抱怨的同学,问一问具体的问题是什么,然后针对性解决。
第二种:更加广泛收集问题,然后列出来表格,归类分析并安排负责人跟进解决,最后定期跟踪进度。
第三种:深入分析表格的中的问题并对问题进行抽象,从架构调优和产品功能的角度去寻找原因,并寻找解决这些问题带来的业务价值,并确定目标拆解路径,最后按照任务推进和跟踪进展。
第四种:从更全局角度去思考此目标与年度目标的关系,与组织发展的关系,思考如何扩大此事的效益,思考如何通过这些事的解决锻炼和培养团队同学。
软件改变世界,我想这已经是一个无可辩驳的事实。我相信作为一名程序员,大多都有一个执念,造轮子,做工具类软件。这里我是用软件,而不是产品。软件和产品还是有一些本质的区别。产品更多的适合大多数人的使用习惯和审美标准,在一定的设计规范和模式指导之下形成的一个软件产品,类似约定成俗吧。
从毕业到工作已经8年了,更多的是完成企业内的一些需求,也是完成一些平台类的系统,有一个好的产品思维,往往会让我们走的更远。也完成过一些下载量比较高的插件和开源软件。
AutoComplate shell 下载量:40k
REST Client Pro 下载量:233
最近看到很多优秀的独立开发者的故事,很是向往,很是羡慕。一方面尝试通过一些业余项目历练自己的技术能力,另一方面尝试用自己擅长的技术改变自己的工作和生活,这也是我写这个个人业余产品的目的。当然这篇文章我想给大家分享一下自己的整个过程。
首先要有一个想法,做什么东西,解决什么问题,把自己奇奇怪怪的想法写在一个地方,通过多次修改和迭代,你会慢慢发现自己想要的,和自己能做的。这里给大家看一下我自己的记录。
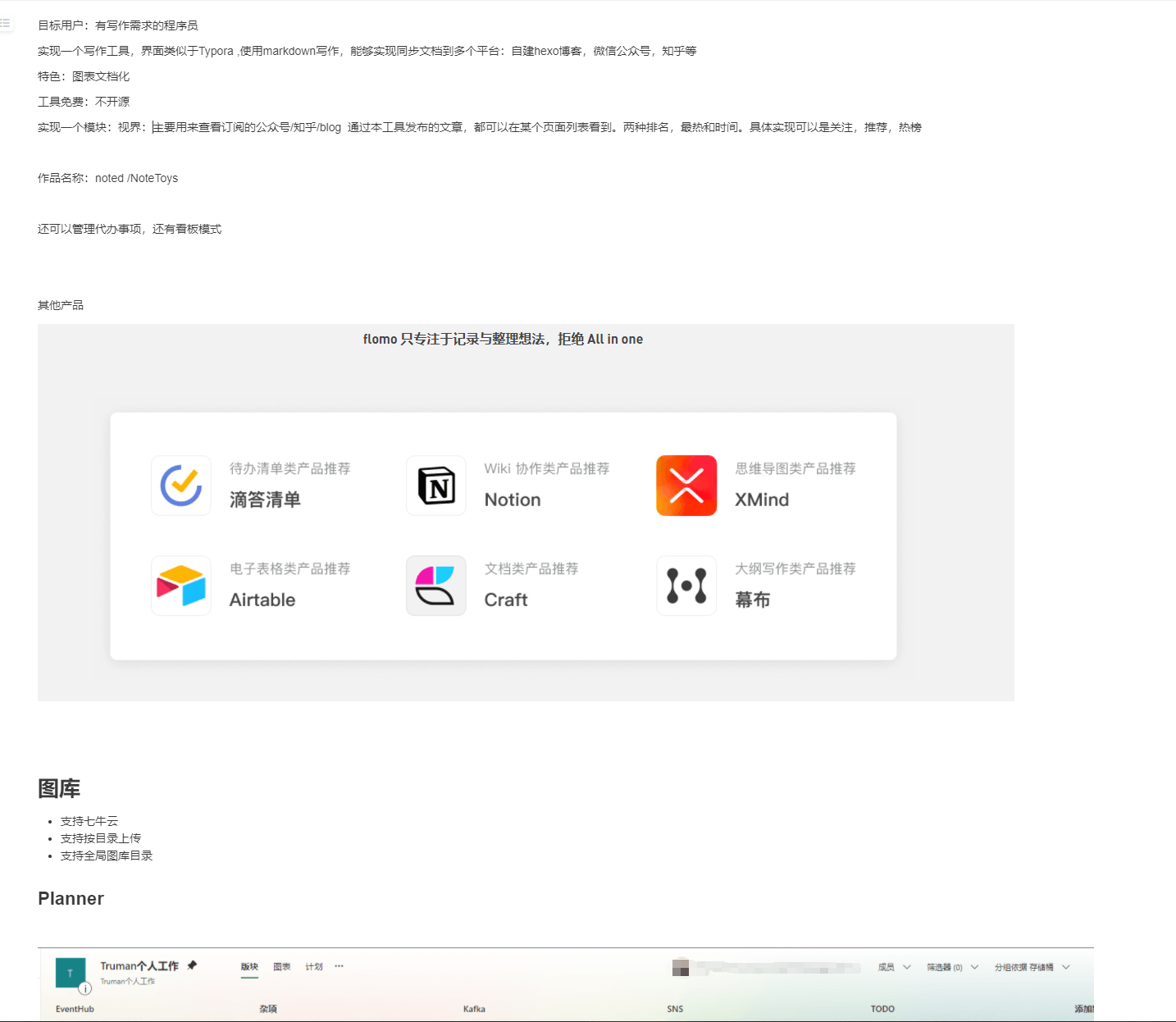
最终做出来的和我在过程中想的却是不同的:
Truman Du Assistant 简称 TDA 个人知识助理
这里我忽略了竞品调研,这一步通常会让你少走很多弯路。目前实现的脑图和看板我觉得对我的工作很有帮助,未来的话,还会再继续增加更多的功能,提升自己工作和学习的效率。
为了保证正常业务不受影响,集群在启用安全功能的过程中还可正常提供服务,可以使用多阶段,多端口,多协议的方案。
本方案以confluentinc/cp-kafka:5.2.1 版本进行试验,SASL机制选择:SASL/SCRAM 特此说明。SCRAM全称为Salted Challenge Response Authentication Mechanism。
Kafka 支持如下SASL机制:
| SASL机制 | Kafka版本 | 特点 |
|---|---|---|
| SASL/OAUTHBEARER | 2.0.0 | 需自己实现接口实现token的创建和验证,需要额外Oauth服务 |
| SASL/Kerberos | 0.9.0.0 | 需要独立部署验证服务 |
| SASL/PLAIN | 0.10.0.0 | 不能动态增加用户 |
| SASL/SCRAM | 0.10.2.0 | 可以动态增加用户 |