一个产品经理的副业日记
最近浏览网页,发现一个产品经理写的笔记,其中一个副业日记有点打动我,一个幽默,乐观的产品经理副业失败日记。
没有歌颂苦难,只有对失败的无限调侃!幽默风趣!记录一下,分享给大家。

最近浏览网页,发现一个产品经理写的笔记,其中一个副业日记有点打动我,一个幽默,乐观的产品经理副业失败日记。
没有歌颂苦难,只有对失败的无限调侃!幽默风趣!记录一下,分享给大家。
之前写过一篇如何监控 kafka 消费 Lag 情况,五年前写的,在 google 上访问量很大,最近正好需要再写这个功能,就查看了最新 API,发现从2.5.0版本后新增了listOffsets方法,让计算 Lag 更简单方便和安全,代码量有质的下降,因为舍弃一些功能,代码精简的了很多。
这里我用最新版做演示,在 pom 文件中增加依赖
1 | <dependency> |
首先初始化 AdminClient
1 | Properties config = new Properties(); |
然后根据 topic 和 groupId 计算 Lag,这种方案要比之前方式优雅了很多。
杜架的记录与分享,记录与思考有价值的信息,主要包含:碎片化思考,阅读笔记分享,开源项目(软件)介绍。内容主题可能有极大的个人喜好偏向,努力做个输出的人,爱我所爱,想我所想,写我所写。

身边不时传来裁员的声音,经济环境感觉是持续下降,不止是在国内,美国也是。作为程序员,我们能怎么创收呢?
曾经想多很多次,也做过一些实践,最近看到的两个文章,给我添加了新的思路,虽然同样是很难。我想分享出来给大家看看,也许能启发你呢。
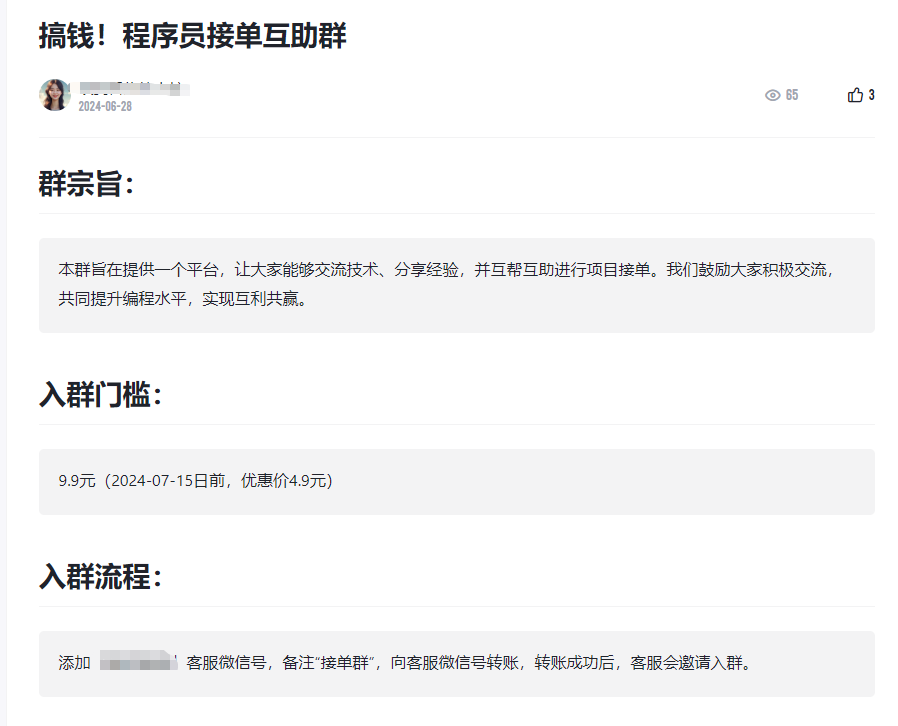
一个是接单互助群,类似于猪八戒,更小的猪八戒。通过整合市场需求和程序员兼职愿景,搞个小规模的,还是可以赚一些钱的。曾经我也做过,只是接单量太小,未来还是可以继续尝试的。两种赚钱模式,一种是入群会费,一种是比例抽成费。
赚想赚钱的人的钱是最容易得,网店,自媒体,AI 等等,这也就是为什么每个风口都是卖课。卖课很好的诠释了赚想赚钱的人的钱是最容易成功的
一个是一对一咨询,打造个人品牌后,一个变现的很好途径和方式,在国外比较常见。我这里想说的不是贬义,确实看到一些人在付费咨询后获得自己想要的,不论是解惑,职业生涯的规划等等。出售自己的时间,了解不同的人,收获不同。

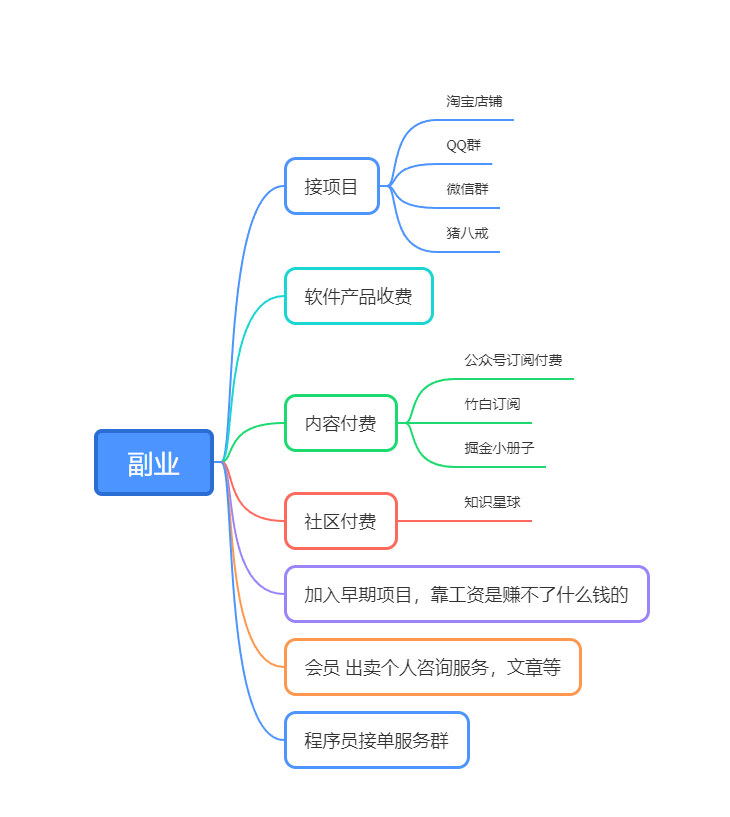
如下是我针对自己副业总结的思维图,有些是构想,有些已经实践,分享出来,希望对你有帮助,也欢迎有想法的找我私聊。声明我目前没有咨询和接单群,不排除未来我会这么做。
杜架的记录与分享,记录与思考有价值的信息,主要包含:碎片化思考,阅读笔记分享,开源项目(软件)介绍。内容主题可能有极大的个人喜好偏向,努力做个输出的人,爱我所爱,想我所想,写我所写。

在 Chrome 浏览器可以获取机器 cpu,gpu,硬盘等信息。原因是 Chromium 内置了一个系统级插件。
这个插件允许 *.google.com 网站获取宿主机 CPU 等信息。
随便打开一个 *.google.com console 里面输入:
1 | chrome.runtime.sendMessage('nkeimhogjdpnpccoofpliimaahmaaome', |
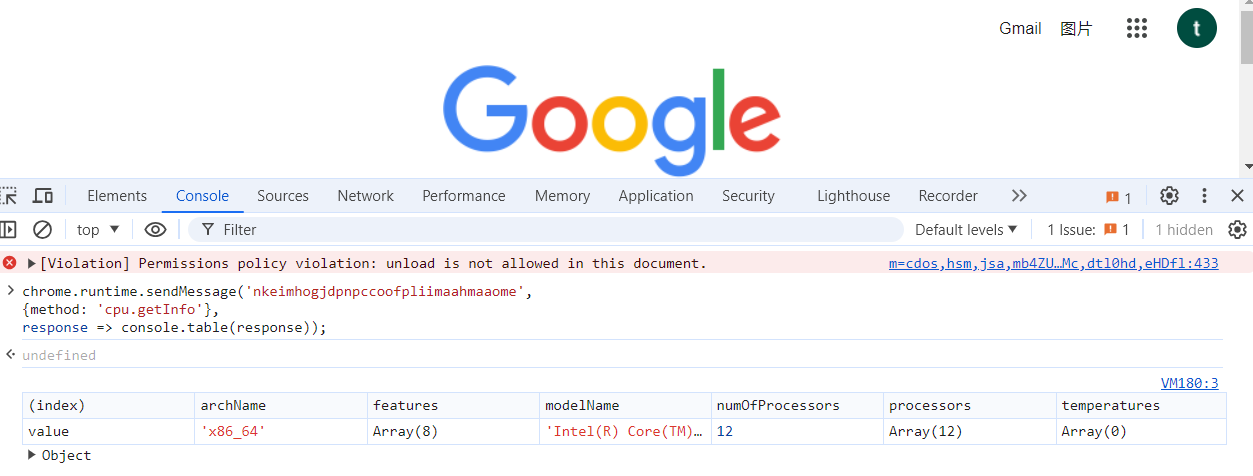
同样在 edge 中测试也可以,通过查看源码还能做更多的事。
前段时间看到一个币圈的新闻,cookie 被浏览器插件劫持,导致账户财务损失惨重,提醒大家要关注插件权限,不要随意安装不知名插件。
从 API 到 Agent:万字长文洞悉 LangChain 工程化设计
本文作者试着从工程角度去理解 LangChain 的设计和使用。大家可以将此文档作为 LangChain 的“10 分钟快速上手”手册,希望帮助需要的同学实现 AI 工程的 Bootstrap。
最近读了两篇文章,一篇是《带你详细了解架构设计》,一篇是《如何成为架构师?》,写的很好,也很认同,推荐有时间的多读几篇原文,本文是对这两篇文章的理解和自己的经验总结。
文章有很多概念,读起来会让人回到中学读书时代,在中学阶段,学生会通过教科书、课堂讲解等方式了解基本概念和定义,比如数学中的几何形状、物理中的力学规律等。
知识学习的套路是建立在掌握基础概念的基础上,通过理论学习与实践相结合、持续练习和复习、拓展知识面和深入学习,以及持续学习和更新来不断提升自己的学习能力和技能水平。
在 IT 技术学习中对于打工人来说有点繁文缛节,太正版,不接地气,顾弄玄虚。我以前这么认为的,不过最近认知升级,有这么一些变化:《能文能武李延年》为什么拍的好,因为它讲明白一件事,我们为什么要打仗,我们要学习架构,是不是应该搞懂为什么需要架构,架构是什么,再扩延一下,5W2H,理论作为指导,和实践相结合,才能一直打胜仗。
说了一堆废话,想说明白自己的一个理解,概念和定义是理论,可以用来指导我们的实践。
杜架的记录与分享,记录与思考有价值的信息,主要包含:碎片化思考,阅读笔记分享,开源项目(软件)介绍。内容主题可能有极大的个人喜好偏向,努力做个输出的人,爱我所爱,想我所想,写我所写。

作者循环渐进讲解了如何从零到一写一个前端脚手架,语言幽默风趣,读完确实收益匪浅。 读完以后,你会学到:
文章关注最实用的技术,忽略相关背景及周边技术介绍,比如高效微调只介绍 LoRA,包含如下内容:
Install Docker Compose v2.14.0 or newer on your workstation.
这里记录一下我在 ubuntu 里升级方法。
首先升级相应的 docker 版本
1 | apt-get update |
由于 ubuntu 镜像源较旧,无法更新到最新版 docker-compose,接下来手动升级 docker-compose。
在手动升级之前,要确保 docker-ce 支持的最高 docker-compose版本。
手动在https://github.com/docker/compose/releases下载 docker-compose 安装包。
首先找到 docker-compose 地址
1 | root@lab:/# which docker-compose |
用下载的文件替换如上文件即可。
杜架的记录与分享,记录与思考有价值的信息,主要包含:碎片化思考,阅读笔记分享,开源项目(软件)介绍。内容主题可能有极大的个人喜好偏向,努力做个输出的人,爱我所爱,想我所想,写我所写。

从 004 开始,源于最早的《杜架的技术月刊》只写了 3 期,由于懒惰就没继续写了,现在想想月刊和周刊都有心理负担,索性想写就写,名称也改为《杜架的记录与分享》,就当记录与思考有价值信息的笔记吧
一个是胃之书 AI,大语言模型 AI 饮食记录员,拍张照片就可以分析食物背后的故事,这个应用我是没有想到的,以此发散思维,LLM 也可以应用在个人记账的场景中。
另一个是可辅助盲人「看见世界」,借助 LLM,TTS 等技术可以让盲人看见世界。
之所以说这两个有价值,和烂大街的 AI 应用相比,确实是我没想到的。
本文案例为 sql server,其他数据源切换为相应的驱动即可。
1 | <dependency> |
1 | # mybatis |
xml 文件省略,保持和 mybatis 一样即可,代码使用上只用在 Mapper 或者 DAO 文件上使用@DS声明即可。
1 | @Mapper |
默认主库为 db1,因此操作 db1 的接口可不用声明。
CUDA 版本
经过测试,Llama-3 只有在 CUDA 新版下才可以运行,CUDA Version: 12.4 验证通过。
代理
在公司内网环境,往往需要代理才能下载模型文件。我这里使用 session 模式下全局。~/.bash.rc
1 | export HTTP_PROXY="http://*.*.*.*:*" |
安装依赖
1 | pip install fastapi==0.110.2 |
llama3-8B 是基本模型,基本上只完成输入提示,但 llama3-8B Instruct 针对指令跟随和多轮对话模板进行了微调,用于助理完成作为聊天响应。
如果你的特定目的是为了聊天完成,那么指令是最好的选择,否则如果它是为了简单的输入完成,那么基本模型就可以了