Kafka 消息生产及消费原理
Kafka 消息生产及消费原理
开篇
关于客户端生产和消费不在本文中探讨,本文主要集中在Kafka服务器端对消息如何存储和如何读取消息。
本文主要探讨如下问题:
- 服务器端接收到消息后如何处理?
- 如果我指定了一个offset,Kafka怎么查找到对应的消息?
- 如果我指定了一个timestamp,Kafka怎么查找到对应的消息?
正文
服务器端接收到消息处理流程
Kafka Server接受消息处理流程

KafkaApis是Kafka server处理所有请求的入口,在 Kafka 中,每个副本(replica)都会跟日志实例(Log 对象)一一对应,一个副本会对应一个 Log 对象。副本由ReplicaManager管理,对于消息的写入操作在Log与LogSement中进行的。
Log append处理流程

真正的日志写入,还是在 LogSegment 的 append() 方法中完成的,LogSegment 会跟 Kafka 最底层的文件通道、mmap 打交道。数据并不是实时持久化的,mmap只是写入了页缓存,并没有flush进磁盘,当满足if (unflushedMessages >= config.flushInterval) 才会真正写入磁盘。
Consumer 获取消息
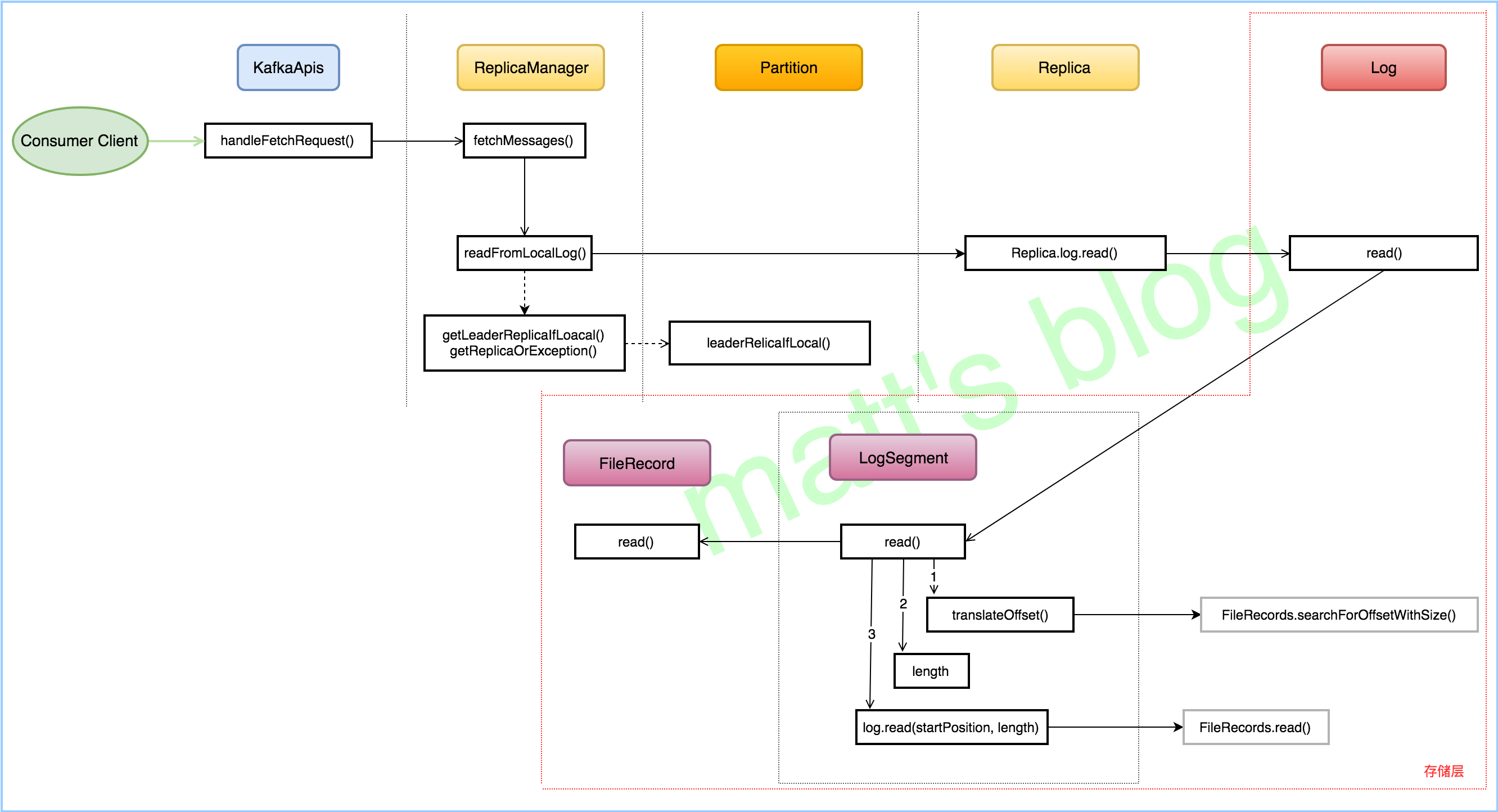
指定offset,Kafka怎么查找到对应的消息
- 通过文件名前缀数字x找到该绝对offset 对应消息所在文件(log/index)
- offset-x为在文件中的相对偏移
- 通过相对偏移在index文件找到最近的消息的位置(使用二分查找)
- 在log文件从最近位置开始逐条寻找
首先根据offset获取LogSegment,即var segmentEntry = segments.floorEntry(startOffset)segmentEntry 是个抽象的对象,包含log、index,timeindex等对象。
接下来在index中获取position(物理位置),即val startOffsetAndSize = translateOffset(startOffset)
源码为:
1 | private[log] def translateOffset(offset: Long, startingFilePosition: Int = 0): LogOffsetPosition = { |
这里说明一下index中根据下标计算偏移量地址与物理地址:物理地址=n*8+4,偏移量地址=n*8
1 | private def relativeOffset(buffer: ByteBuffer, n: Int): Int = buffer.getInt(n * entrySize) |
最后根据position在log中截取相应的message,log.slice(startPosition, fetchSize)
1 | public FileRecords slice(int position, int size) throws IOException { |
看到searchForOffsetWithSize有个疑问,上面代码显示返回给客户端的records是批量的,假如提交的offset是这批次的中间一个,那么返回给Consumer的message是有已经被消费过的信息,我感觉不可能是这样的,查看了server端代码,再未发现删除已消费的message逻辑。
Kafka设计者真的这么蠢??
随后我查看了客户端consumer源码有发现到如下代码:if (record.offset() >= nextFetchOffset)有对大于指定offset消息抛弃的逻辑。
1 | private Record nextFetchedRecord() { |
至此得出结论:为了提高server端的响应速度,没有对批量消息进行解压缩,然后精准返回指定信息,而是在客户端解压消息,然后再抛弃已处理过的message,这样就不会存在重复消费的问题。这个问题纠结了半天,不知是否正确,仅是自己的理解,如果有哪位同学对这里有研究,欢迎指出问题。
指定timestamp,Kafka怎么查找到对应的消息
略
类似根据offset获取消息,不过中间是从timeindex中获取position,然后遍历对比timestamp,获取相应的消息。