MongoDB指南
MongoDB 是通用、基于文档的分布式数据库。支持完整的 ACID 事务,具有强大的查询语言等。属于NoSQL数据库。
基本概念
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
SQL术语/概念MongoDB术语/概念解释/说明databasedatabase数据库tablecollection数据库表/集合rowdocument数据记录行/文档columnfield数据字段/域indexindex索引table joins表连接,MongoDB不支持primary keyprimary key主键,MongoDB自动将_id字段设置为主键SQL术语/概念MongoDB术语/概念解释/说明databasedatabase数据库tablecollection数据库表/集合rowdocument数据记录行/文档columnfield数据字段/域indexindex索引table joins表连接,MongoDB不支持primary keyprimary key主键,MongoDB自动将_id字段设置为主键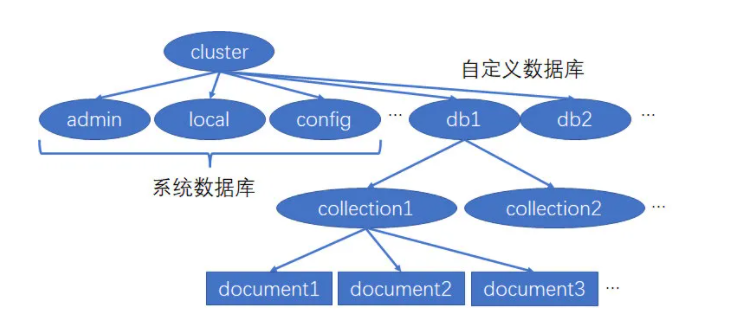
适用场景与选型
MongoDB定位与优点
- OLTP数据库
- ACID事务
- 横向扩展能力,数据量和并发量增加时候架构可以自动扩展
- JSON数据结构 ,适合微服务/REST API
- 灵活模型,适合迭代开发,数据模型多变的场景
基于功能选择
| 支持功能 |
|---|
| 亿及以上数据量 |
| 灵活表结构 |
| 高并发读/写 |
| 跨地区集群 |
| 分片集群 |
| 地理位置查询 |
| 聚合计算 |
| 异构数据 |
| 大宽表 |
支持功能亿及以上数据量灵活表结构高并发读/写跨地区集群分片集群地理位置查询聚合计算异构数据大宽表支持功能亿及以上数据量灵活表结构高并发读/写跨地区集群分片集群地理位置查询聚合计算异构数据大宽表### 基于场景选择
- 移动应用
- 商品信息
- 内容管理
- 物联网
- Saas
- 主机分流
- 实时分析
- 关系型数据库替换
MongoDB全家桶
| 软件模块 | 解释 |
|---|---|
| mongod | MongoDB数据库守护进程 |
| mongo | MongoDB Cli |
| mongos | MongoDB 路由进程,分片环境下使用 |
| mongodump/mongorestore | 命令行数据库备份与恢复工具 |
| mongoexport/mongoimport | csv/json导入与导出工具 |
| Compass | MongoDB GUI管理工具 |
软件模块解释mongodMongoDB数据库守护进程mongoMongoDB ClimongosMongoDB 路由进程,分片环境下使用mongodump/mongorestore命令行数据库备份与恢复工具mongoexport/mongoimportcsv/json导入与导出工具CompassMongoDB GUI管理工具软件模块解释mongodMongoDB数据库守护进程mongoMongoDB ClimongosMongoDB 路由进程,分片环境下使用mongodump/mongorestore命令行数据库备份与恢复工具mongoexport/mongoimportcsv/json导入与导出工具CompassMongoDB GUI管理工具## 环境搭建
1 | docker run -d --net=host --name mongo mongo:5.0.2-focal |
这样就可以在本地启动一个MongoDB服务,默认开启mongos端口是 27017。
CRUD操作
使用 mongosh命令即可进入Cli工具,如果是有密码的,可以使用如下命令:
1 | mongosh mongodb://root:root@localhost:27017/truman_test?retryWrites=false |
数据库DDL
1 | // 创建/切换到指定数据库 |
集合DDL
1 | // 创建collection |
文档DDL
1 | // 插入文档 |
查询
1 | truman_test> db.all_raw_data.find().pretty() |
查询语法:

Spring Data MongoDB使用
推荐两个官网文档:Accessing Data with MongoDB 、Spring Data MongoDB
首先在项目中引入依赖:
1 | <dependency> |
配置参数与定义实体
首先在配置文件增加mongo配置信息
1 | spring.data.mongodb.uri=mongodb://localhost:27017/truman_test?retryWrites=false |
然后新增实体
1 | @Document("all_raw_data") |
编写Repository
定义 RawDataRepository继承 MongoRepository,这样就可以不用写任何代码,实现数据的增删改查,基本用法和Spring JPA类似。
1 | public interface RawDataRepository extends MongoRepository<NotificationRawData, String> { |
公共CRUD
1 | <S extends T> S save(S var1); |
自定义查询
1 | //根据状态统计数量 |
分页查询
1 | // 从下标0开始读取,读取1条记录 |
聚合查询
MongoDB 提供了三种执行聚合的方法:聚合管道,map-reduce 和单一目的聚合方法(如 count、distinct 等方法)。
聚合管道
1 | pipeline = [$stage1, $stage2, ...$stageN]; db.collection.aggregate( pipeline, { options } ) |
例如:
1 | db.orders.aggregate([ |
该例子分为两个阶段:1.match 2.group
map-reduce
在5.0中标记废弃。聚合管道性能要比map-reduce更好。
单一目的聚合
1 | db.collection.estimatedDocumentCount() |
事务
//TODO
索引
MongoDB具有丰富的索引方式,有10种以上,如果没有索引,读操作必须扫描集合中的每个文档并删选相关记录。
这里只检查介绍三种,更多的介绍和使用详见官方文档。
- 单字段索引 :
db.records.createIndex( { score: 1 } )1代表升序 - 文本索引 :
db.records.createIndex( { comments: "text" } )支持对字符串内容的文本搜索查询,一个集合最多可以有一个文本索引,一个文本索引可以支持模糊设置来支持多个字段。 - ttl索引 :
db.records.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } ),支持在一定的时间或特定的期限后自动从集合中删除文档,默认60秒运行一次删除过期文档。
架构设计
在MongoDB中为了服务的高可用,增加了复制集;高性能,增加了分片集。倒不是一个MongoDB数据库必须有这两个,而是根据需要来设计自己的MongoDB部署架构。了解这个架构设计,对我们代码实现和自己系统架构设计都很有帮助。
复制集
复制集又称为副本集(Replica Set),是一组维护相同数据集合的 mongod 进程。复制集包含多个数据节点和一个可选的仲裁节点(arbiter)。在数据节点中,有且仅有一个成员为主节点(primary),其他节点为从节点(secondary)。
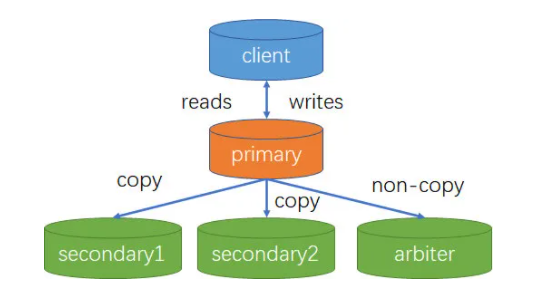
复制集节点类型
- 主节点(Primary): 接受所有的写操作
- 从节点(Secondary):从主节点复制数据到自己节点上,可以配置投票权,是否对客户端可见,选主优先级等
- 仲裁节点(Arbiter):该节点不保存数据
复制集作用
- 作为主节点备份,以实现 failover。
- 将数据从一个数据中心复制到另一个数据中心,减少另一个数据中心的读延迟。
- 实现读写分离。
- 实现容灾,可以在数据中心故障时快速切换到同城或异地的数据中心。
分片集
MongoDB是通过分片实现水平扩展。
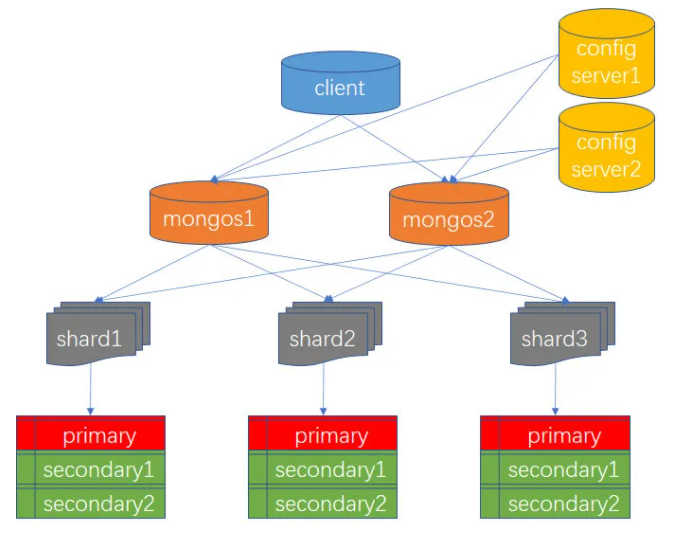
分片集组件
- shard:每个分片上可以保存一个集合的子集,所有分片上的子集的数据互不相交,构成完整的集合。每个分片可以被部署为复制集架构。最大为 1024 个分片
- mongos:查询路由器
- config server:存储分片集的相关配置信息
分片操作
首先先启动 shard,mongos,config server.
加入分片
db.runCommand({ addshard:"localhost:27020" })设置分片集存储数据库
db.runCommand({ enablesharding:"test" })增加集合分片键
db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}})其中增加分片集语法为
sh.shardCollection(<namespace>, <key>)namespace “
. “ key
<shard key field1>: <1|"hashed">1代表的按范围划分
hashed代表使用hash划分
集群模式
- 使用复制集实现,两地三中心,1个Primary,4个Secondary
- 使用分片集,全球多写集群(Global Cluster)两个location各两个Primary,两个Secondary
- 独立集群模式,使用第三方工具同步数据(Tapdata/Mongoshake)
问题与经验
document能存储最大数据?
MongoDB默认的BSON最大支持16M,对于超过16M的场景,可以考虑使用MongoDB GridFS。