Elasticsearch Mapping Best Practice
Mapping 各字段的选型流程
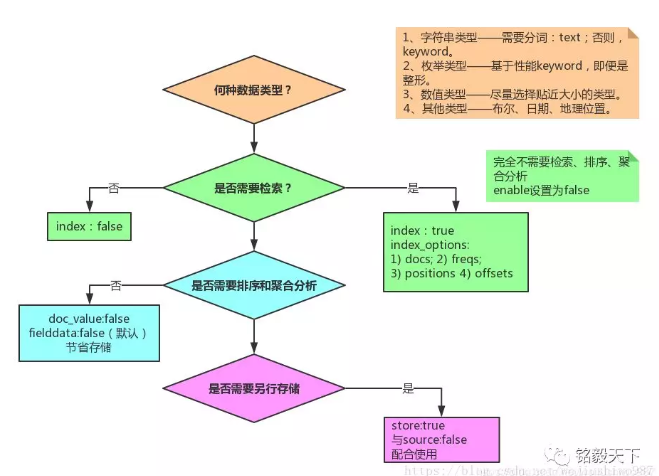
规则
elasticsearch 为了更好的让大家开箱即用,默认启用了大量不必要的设置,为了降低空间使用,提升查询效率,请按以下规则构建最佳的 Mapping
1. 禁用不需要的功能
不用查询,禁用 index
1 | PUT index |
不关心评分,禁用该功能
1 | PUT index |
不需要短语查询,禁用 index positions
1 | PUT index |
2. 不要使用默认的 Mapping
默认 Mapping 的字段类型是系统自动识别的。其中:string 类型默认分成:text 和 keyword 两种类型。如果你的业务中不需要分词、检索,仅需要精确匹配,仅设置为 keyword 即可。
根据业务需要选择合适的类型,有利于节省空间和提升精度。
1 | PUT index |
3. 考虑 identifiers 映射为 keyword
某些数据是数字的事实并不意味着它应该始终映射为数字字段。 Elasticsearch 索引数字的方式可以优化范围查询,而 keyword 字段在 term 查询时更好。
通常,存储诸如 ISBN 的标识符或标识来自另一数据库的记录的任何数字的字段很少用于范围查询或聚合。这就是为什么他们可能会受益于被映射为 keyword 而不是 integer 或 long。