kafka 源码 idea 开发环境搭建
前言
为了深入研究kafka运行原理和架构,很有必要搭建开发环境,这样我们就很方便的debug 服务。
前期准备
- Gradle 5.0+
- jdk8
- Scala 2.12
- idea scale plugin
配置/运行
- 首先执行在源码目录下执行
gradle - 然后build
./gradlew jar - 最后生成idea工程
./gradlew idea
运行MirrorMaker
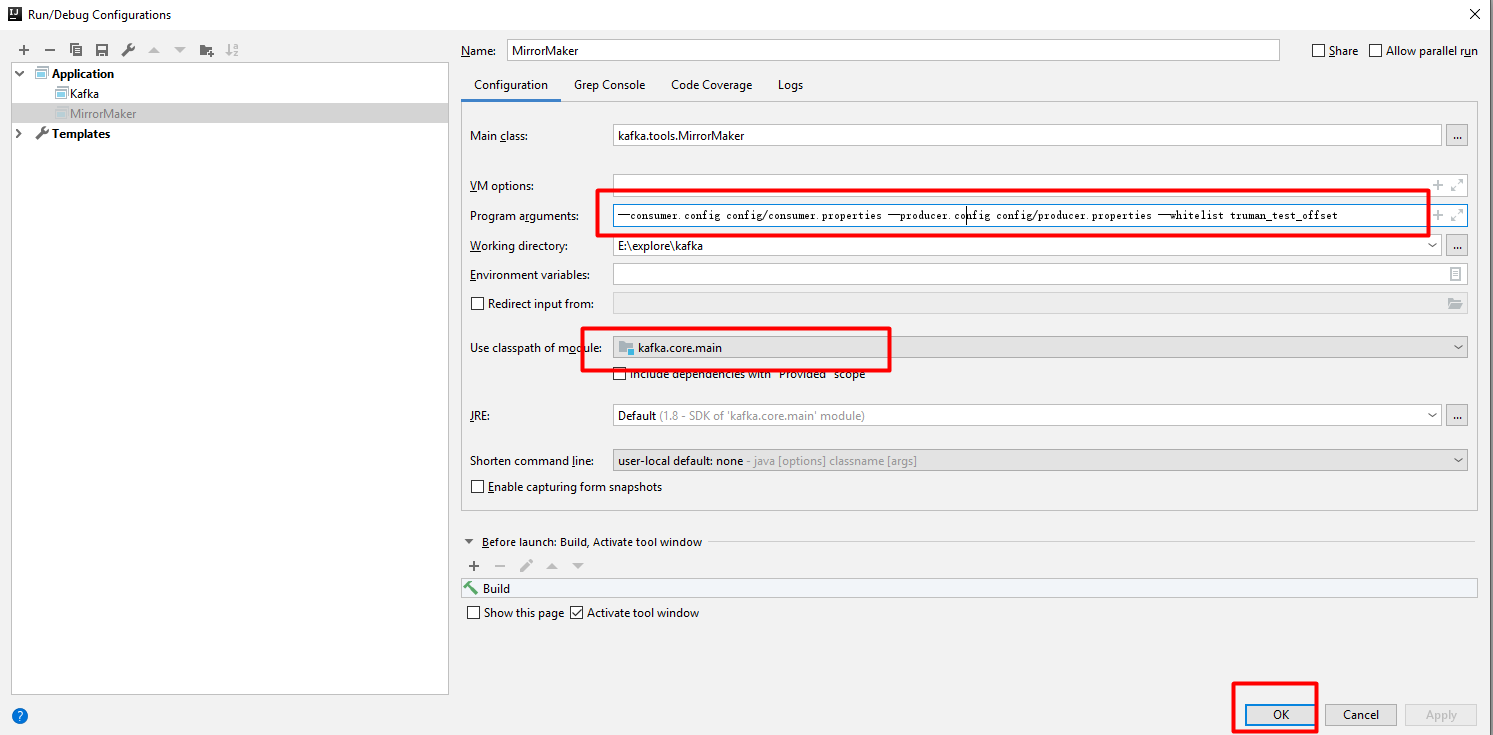
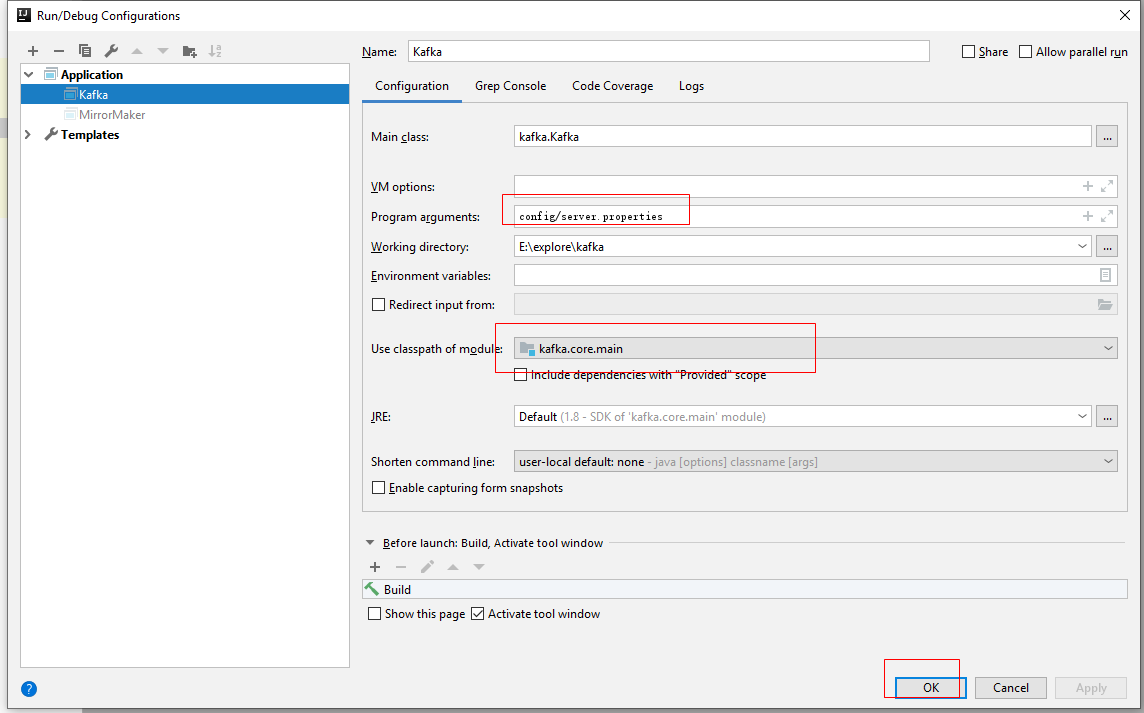
运行kafka server
因为kafka依赖zookeeper,在开始之前请先启动一个zookeeper服务,本文章略。
错误总结
无log
然后在modules中找到core/main,将这两个依赖导入进来即可
最后将config目录下的log4j.properties复制到core/main/scala目录下(如果还是无法看到log,可以将该文件复制到out/production/classes目录下)
执行报错,无法找到相关类
执行./gradlew jar即可解决。
Core源码模块解读
| 模块名程 | 说明 |
| admin | kafka的管理员模块,操作和管理其topic,partition相关,包含创建,删除topic,或者拓展分区等。 |
| api | 主要负责数据交互,客户端与服务端交互数据的编码与解码。 |
| cluster | 这里包含多个实体类,有Broker,Cluster,Partition,Replica。其中一个Cluster由多个Broker组成,一个Broker包含多个Partition,一个Topic的所有Partition分布在不同的Broker中,一个Replica包含都个Partition。 |
| common | 这是一个通用模块,其只包含各种异常类以及错误验证。 |
| consumer | 消费者处理模块,负责所有的客户端消费者数据和逻辑处理。 |
| controller | 此模块负责中央控制器的选举,分区的Leader选举,Replica的分配或其重新分配,分区和副本的扩容等。 |
| coordinator | 负责管理部分consumer group和他们的offset。 |
| log | 这是一个负责Kafka文件存储模块,负责读写所有的Kafka的Topic消息数据。 |
| message | 封装多条数据组成一个数据集或者压缩数据集。 |
| metrics | 负责内部状态的监控模块。 |
| network | 该模块负责处理和接收客户端连接,处理网络时间模块。 |
| security | 负责Kafka的安全验证和管理模块。 |
| serializer | 序列化和反序列化当前消息内容。 |
| server | 该模块涉及的内容较多,有Leader和Offset的checkpoint,动态配置,延时创建和删除Topic,Leader的选举,Admin和Replica的管理,以及各种元数据的缓存等内容。 |
| tools | 阅读该模块,就是一个工具模块,涉及的内容也比较多。有导出对应consumer的offset值;导出LogSegments信息,以及当前Topic的log写的Location信息;导出Zookeeper上的offset值等内容。 |
| utils | 各种工具类,比如Json,ZkUtils,线程池工具类,KafkaScheduler公共调度器类,Mx4jLoader监控加载器,ReplicationUtils复制集工具类,CommandLineUtils命令行工具类,以及公共日志类等内容。 |