kafka consumer 源码分析(一)Consumer处理流程 开篇 在开始这篇之前,先抛出问题,这章主要通过研究consumer源码解决如下问题:
consumer处理流程
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
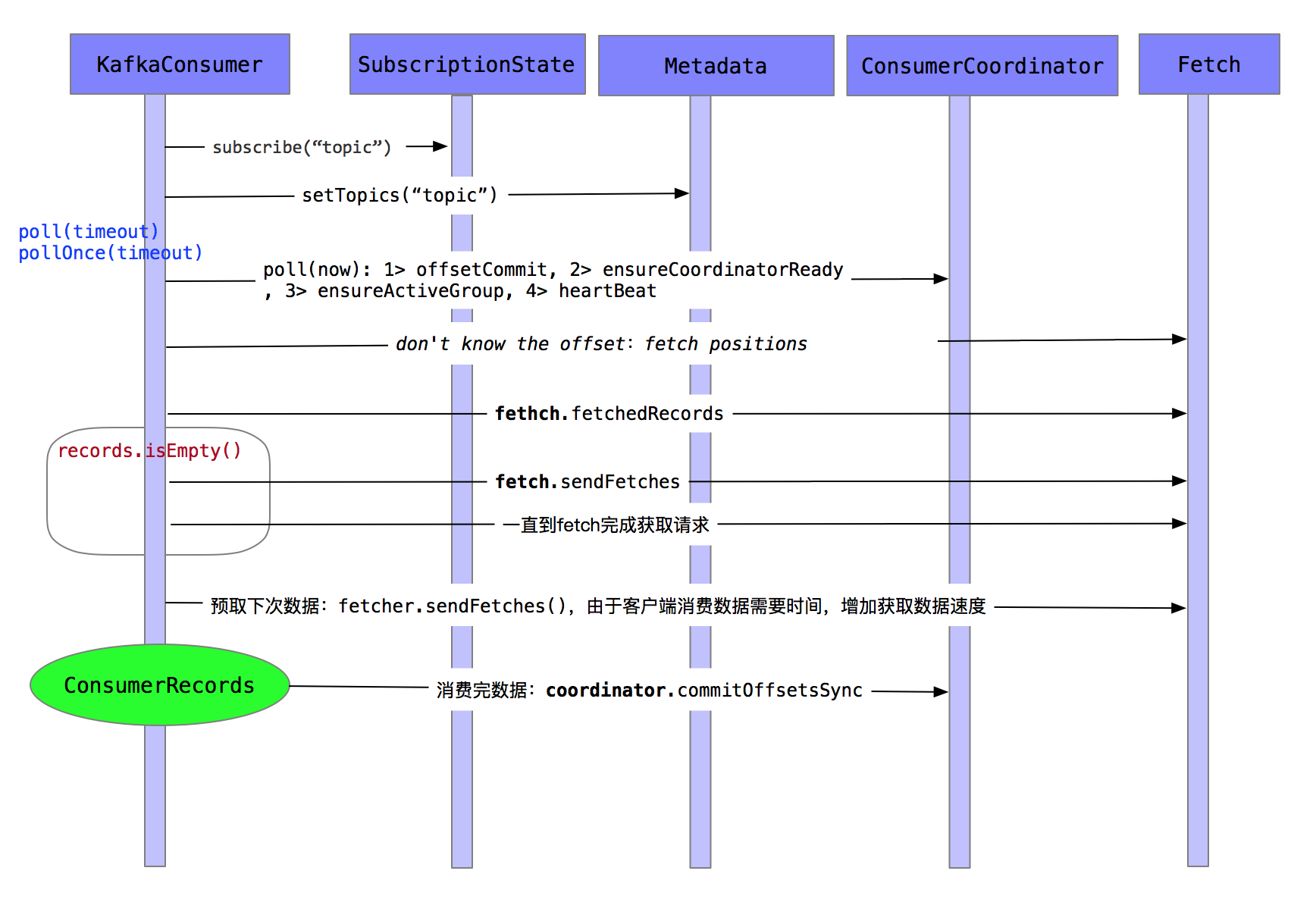
正文 Consumer处理流程 核心组件 ConsumerCoordinator : 消费者的协调者, 管理消费者的协调过程
维持coordinator节点信息(也就是对consumer进行assignment的节点)
维持当前consumerGroup的信息, 当前consumer已进入consumerGroup
Fetcher : 数据请求类
ConsumerNetworkClient : 消费者的网络客户端,负责网络传输的流程
SubscriptionState : 订阅状态类
Metadata : 集群的元数据管理类,使用租约机制
工作流程
消费者提交消费位移源码追究 查看官方API文档 ,在描述如何手动提交offset,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 try { while (running) { ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE); for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> record : partitionRecords) { System.out.println(record.offset() + ": " + record.value()); } long lastOffset = partitionRecords.get(partitionRecords.size() - 1 ).offset(); consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata (lastOffset + 1 ))); } } } finally { consumer.close(); }
The committed offset should always be the offset of the next message that your application will read. Thus, when calling commitSync(offsets)
意思是在调用commitSync(offsets)必须是当前offset+1。
其实我很想知道,自动提交offset方式(包含不指定offset,例如:commitSync()),具体源代码在哪里**+1**。
经过孜孜不倦的翻阅代码,感觉好像看懂了一点点,就把自己看懂的那点写出来,如果不对的话,欢迎看到的同学帮忙纠正一下,当不胜感激!
这里就只探究自动提交offset的情形,因为涉及的代码较多,这里只给出相应的关键代码。
1 2 3 4 5 6 7 8 9 10 public void commitSync (Duration timeout) { try { if (!coordinator.commitOffsetsSync(subscriptions.allConsumed(), time.timer(timeout))) { ...略 } } finally { release(); } }
1 2 3 4 5 6 7 8 9 public Map<TopicPartition, OffsetAndMetadata> allConsumed () { Map<TopicPartition, OffsetAndMetadata> allConsumed = new HashMap <>(); for (PartitionStates.PartitionState<TopicPartitionState> state : assignment.partitionStates()) { if (state.value().hasValidPosition()) allConsumed.put(state.topicPartition(), new OffsetAndMetadata (state.value().position)); } return allConsumed; }
下来只用查看到什么时候更新state中信息,即可知道提交的offset是如何计算的,首先我们要知道一个知识点,consumer非多线程处理逻辑,因此每次提交offset都是在poll中处理的,因此我们需要查看poll中的逻辑,接着往下看。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer); | V final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); | V List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining); | V long nextOffset = partitionRecords.nextFetchOffset; log.trace("Returning fetched records at offset {} for assigned partition {} and update " + "position to {}" , position, partitionRecords.partition, nextOffset); subscriptions.position(partitionRecords.partition, nextOffset);
这里其实已经看到答案,但是可能有同学还会问,不是说更新state吗?这里更新的是 subscriptions.position,接着往下看
1 2 3 4 5 6 7 8 9 10 public void position (TopicPartition tp, long offset) { assignedState(tp).position(offset); } private TopicPartitionState assignedState (TopicPartition tp) { TopicPartitionState state = this .assignment.stateValue(tp); if (state == null ) throw new IllegalStateException ("No current assignment for partition " + tp); return state; }
终于一切真相大白!看了两天源码,累的要死!Enjoy!
参考
The committed offset should always be the offset of the next message that your application will read KafkaConsumer 流程解析