KafkaSummit2020-Apache Kafka-TheNext10Years
Kafka Summit 2020 -Apache Kafka - The Next 10 Years
前言
Kafka在Confulent成立后发展很快,很明显的变化是发布了很多重大的版本。了解未来的规划,对于我们学习和使用kafka有很大的意义。
Kafka Summit 2020 已经在8-24召开,最近抽出时间看了一些视频,由于自己英语是二把刀,因此本文是自己对该主题的自己理解,尽可能还原Gwen Shapira 的分享(Apache Kafka - The Next 10 Years),中文全网唯一。
Kafka 设计原则
High Performance from First Principles
Principles in Action: Elasticity
Principles in Action: Scalability
Principles in Action: Operationally Friend
Design Considerations in Action
- 数据层面 KIP-405: Kafka Tiered Storage
- 控制层面 KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum
KIP-405: Kafka Tiered Storage
Kafka数据在流式中通常使用尾部读取。尾部读取利用操作系统的页面缓存来提供数据,而不是磁盘读取。旧数据和故障恢复通常会从磁盘读取,这些通常很少见。
在分层存储方法中,Kafka集群配置了两层存储-本地和远程。本地层与当前的Kafka相同,使用Kafka broker上的本地磁盘存储日志段。新的远程层使用HDFS或S3等系统来存储完整的日志段。对应于每个层定义了两个单独的保留期。启用远程层后,可以将本地层的保留期从几天显着减少到几个小时。远程层的保留期可能会更长,几天甚至几个月。当日志段在本地层上滚动时,它将与相应的偏移量索引一起复制到远程层。延迟敏感的应用程序执行尾部读取,并利用现有的Kafka机制从本地层提供服务,该机制有效地使用页面缓存来提供数据。回填和应用程序从故障层恢复,需要比本地层中的数据更旧的数据从远程层提供服务。
该解决方案允许扩展存储独立于Kafka集群中的内存和CPU的存储,从而使Kafka成为长期存储解决方案。这也减少了在Kafka代理上本地存储的数据量,因此减少了在恢复和重新平衡期间需要复制的数据量。远程层中可用的日志段无需在代理上还原或延迟还原,而是从远程层提供。这样,增加保留期不再需要扩展Kafka群集存储和添加新节点。同时,总体数据保留时间仍然可以更长,从而无需使用单独的数据管道来将数据从Kafka复制到外部存储,就像目前在许多部署中所做的那样。
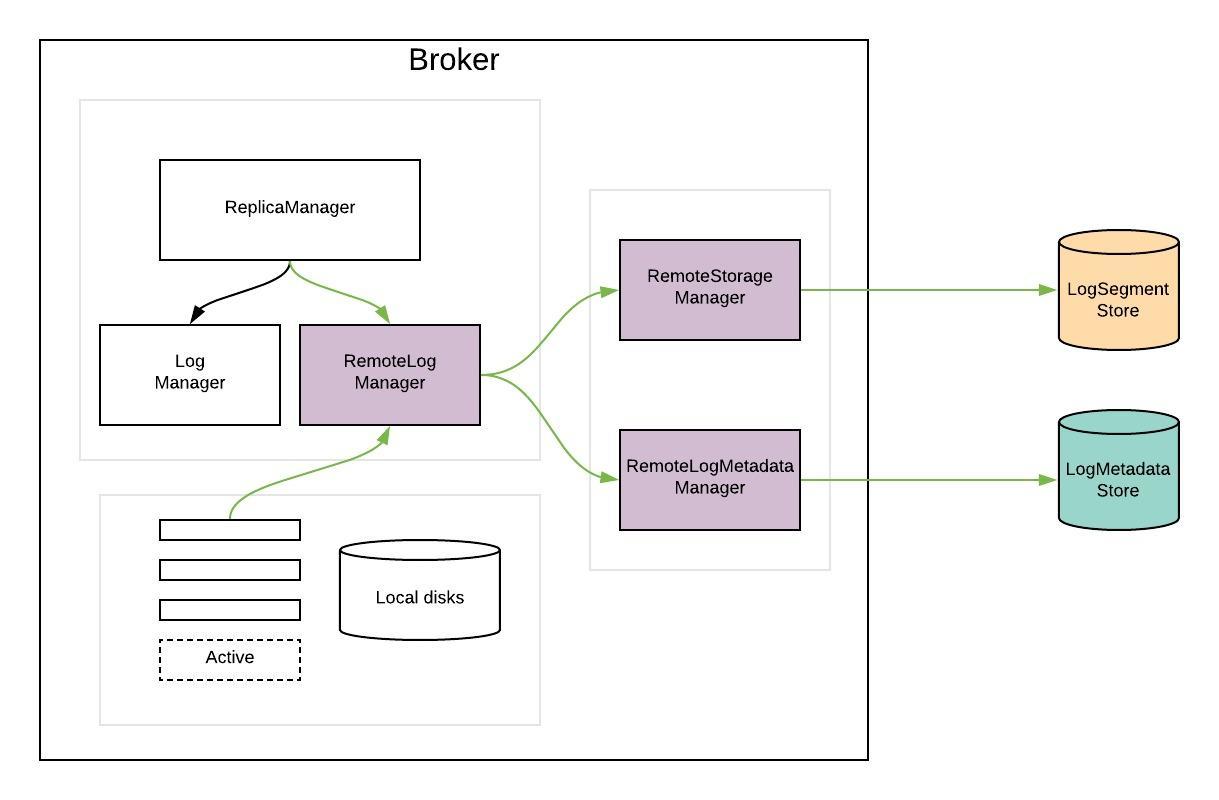
KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum

主要目的是让部署更简单,配置更简单,用log存储元数据。
主要解决的两三个问题:The Controller Quorum和Broker Metadata Management,以及The Broker State Machine
下一代Kafka架构
更插件化,更弹性,更像云服务一样
Elastic
增加,移除brokers更弹性
Integrated
像使用log一样使用kafka,可以很好的和其他系统集成:像S3、HDFS 等所有的存储系统
Infinite
无限存储,你可以增加更多的broker,没有任何限制,并且不会影响性能。