杜架的记录与分享(013期)
杜架的记录与分享,记录与思考有价值的信息,主要包含:碎片化思考,阅读笔记分享,软件分享,内容记录等。内容主题有极大的个人喜好偏向,爱我所爱,想我所想,写我所写。

李渊在隋朝任岐州刺史时住武功,李世民在此出生。李世民即位后,改旧宅为庆善宫,将其生母窦穆皇后常居之别墅改为报本寺。报本寺现已不存,塔为楼阁式砖塔,空心,平面呈八角形,底边长 4.75 米,共七层,高 36.961 米。1994 年因塔身严重倾斜拆除重建。
思考
99%的人没意识到,ChatGPT 是你这辈子能交到的最厉害最贴心的朋友,它上知天文下知地理,在你无助的时候,可以给你专业又靠谱的建议和解决方案。
对于未知领域,LLM 是你进入该领域最靠谱的助手,不管你信与不信,它已经改变了现有的开发模式,极大的提升了开发效率。
除了文本理解能力,文本处理能力,逻辑推理能力以外,我觉得在其他几个方面,目前它已经做得很好,未来还会有更强的能力。
1.编程领域
两个比较火的工具 windsurf ,cursor有很多人不懂编程,用这个编程软件快速开发了许多 App,效果惊人。
最早接触 AI 编程,感觉能力很差,现在越来越强了,越早拥抱,越早收益。
2.搜索
我在开发中遇到的问题,第一时间是问 chatGPT,其次才去谷歌,基本已经解决 98%问题。
3.Computer use
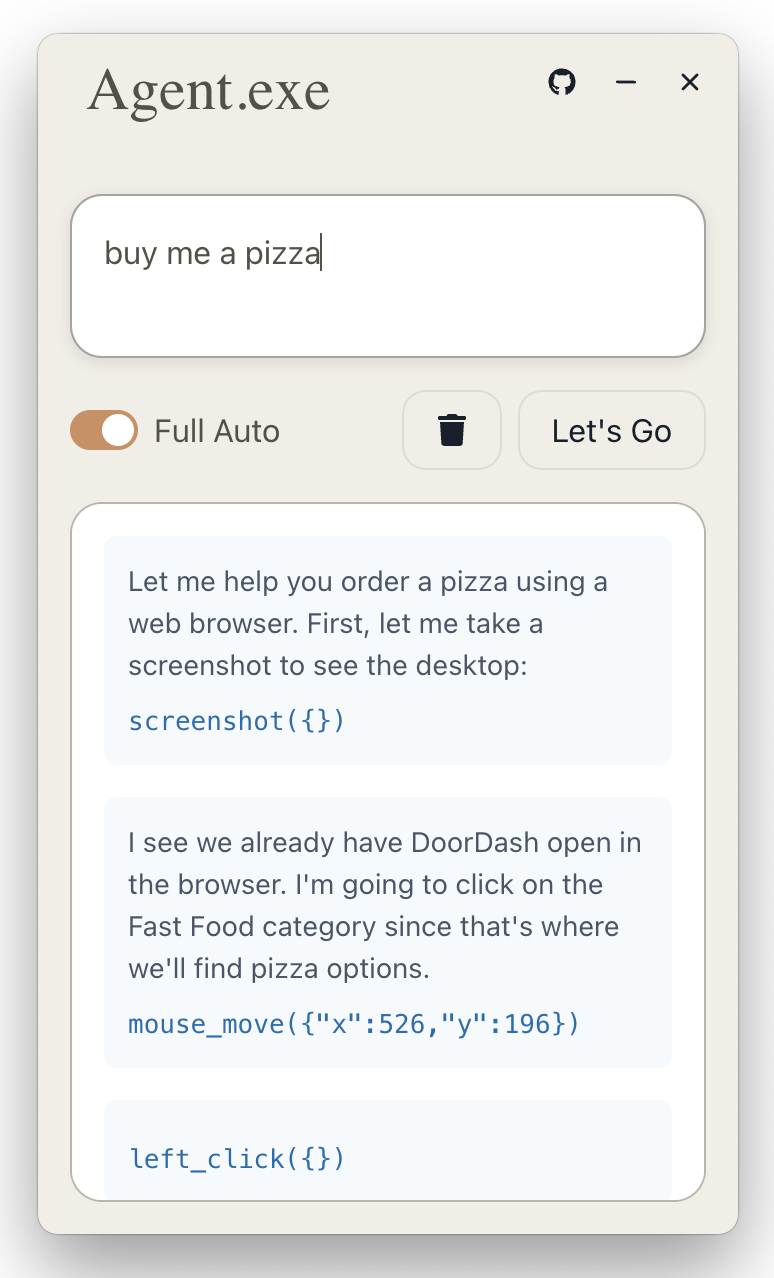
这个标题想了很久,本来想叫工具使用,但又想和之前的调用 funtion 区别开,想到 claude 发布的 Computer use 相对好点,所以暂且叫这个名字。
最早的 AI Agent 人工智能体标配的一个功能就是调用外部函数的能力,这些函数是提前编码写好的,而 Computer use 不再局限于函数,而是全面拥抱 Computer,这样的好处是非计算机领域的一些劳动密集型会带来极大的提升。
想一想这么一个场景,你有一个需求,说给 AI 听,然后他就可以分析你说的话,自己完成你交代它的任务,需求转化为业务往往很难。将以前的自动化直接对接 AI,肯定会带来极大的提升。
现阶段有这么几个项目已经具备基本功能,对于这个方向,我持续看好。
https://github.com/corbt/agent.exe
4.图像识别
给一张图,AI 会给出描述图片中有什么,相当于给盲人眼睛,未来这里一定有颠覆应用诞生,目前最大的问题不是识别准确,而是处理速度。能达到实时处理,那是不是就可以实现快速分析监控视频。此领域应该也是大有可为。
聊聊最近做了什么
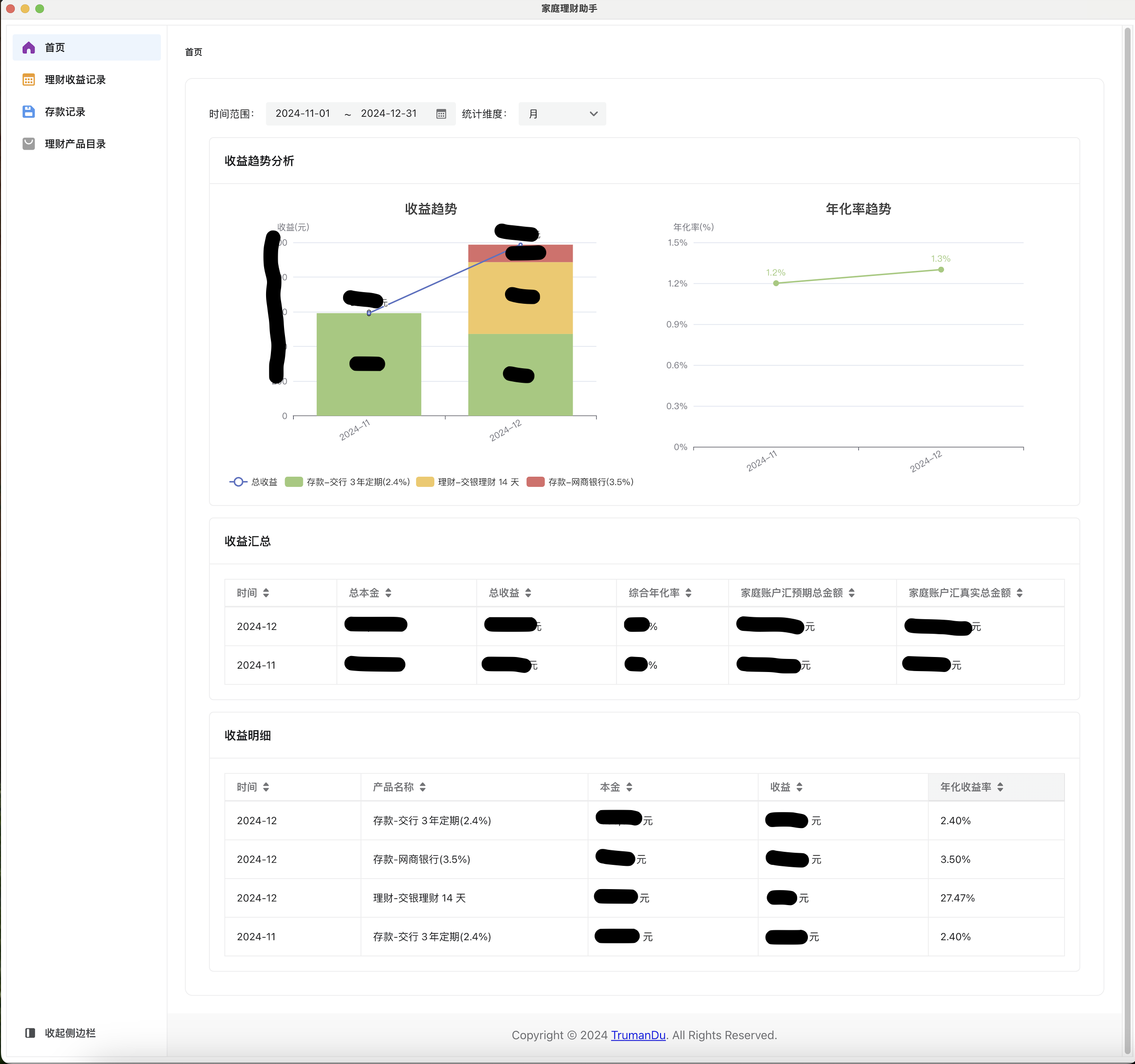
硬件
国补最近进行的如火如荼,趁此时机入手了很多装备,最值得分享的是 MacbookPro 和 4K 27 寸显示器,ROG 魔导士 RX LP 矮光轴机器键盘,再加上自己原本很早买的逻辑 Master 3s 鼠标,生产力大幅提升。

很大一部分时间花在配置机器,安装软件过程中,所以就顺手写了《我的电脑装机软件清单》。
较 windows 生态确实有些变化,总体来说,一个不怎么使用快捷键的人也在尝试使用快捷键,对于我来说这大概是最大的不同,其次是重度使用终端程序解决日常问题。很多软件给了我在 windows 平台从来也不会有的想法和思路。
开源软件
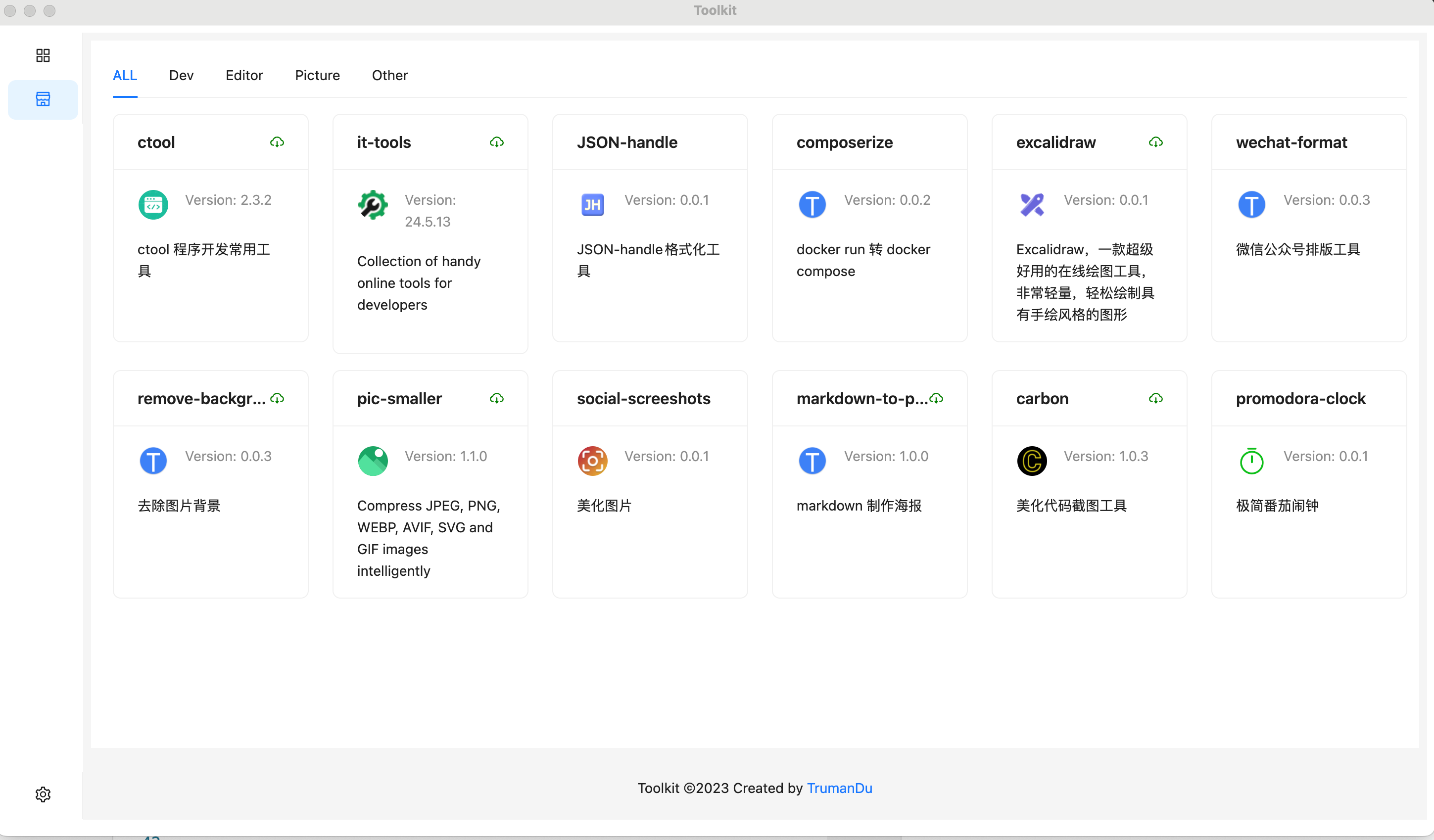
Toolkit
https://github.com/TrumanDu/toolkit
最近升级了软件版本,主要完成以下功能:
- 修改配置和插件目录,避免升级后需要重新安装插件
- 重构代码,修复自动升级 bug
- add plugin session store
- 支持 MacOS
- 升级 electron=31.7.5
- 增加统计链接
- 修改若干 bug
又新增了几个插件,后面会简单介绍一下,更新一下目前支持的插件列表。
我的电脑装机软件清单
最近把公司的电脑和新入手的 Macbook 安装了软件,顺手整理了一下不同平台自己的装机清单,作为记录!
Windows
装机必备
开发必备
- vs code
- intellij idea
- PyChram
- git
- Bbeaver
- NVM
- wsl window 子系统
- Docker Desktop
- MobaXterm SSH 远程工具
编程语言
写作与阅读
效率工具
其他
为何写作与如何写作
写这篇文章,有两个原因:1、有人在微信群问我如何写作 2、前端时间独立站blog 流行的一个问卷。以此为契机回答两个问题:
- 为何写作
- 如何写作
为何写作
先回答一下blog 流行的一个问卷中的几个问题
1. 简单介绍下自己或者你的博客?
严格意义上说,我有两个写作的站点:
blog: 技术笔记,个人简历,豆腐渣文字
book: 多个专业,体系知识库
2. 什么契机让你开始写博客?
2016 年 3 月 12 日写下自己的第一篇文章Markdown-语法学习, 从此 blog 主要用来记录技术学习笔记,偶尔发泄一丝多愁善感的思绪,还有一个作用就是当做自己的简历,让网络上的一些想了解我的同行有个初步印象。随着越写越多,我发现知识是需要整理的,知识往往是成体系的,经常更改单个文章有点困难,因此就有 book 站点。
从2022 年 2 月 5 日开始构建了 book 站点,该站点为成体系知识库,经常会更新整理。
3. 运营博客的过程中是否有失去过动力?如果有,是为什么恢复的?如果没有,请问您又是如何保持创作的激情?
没有,想写就写,写作难的是让自己坐下来写出第一行文字,没有功利性的输出,也就不存在什么动力。
4. 如何搭建博客,以及运营博客每年需要投入的资金?
Hexo & NexT主题,阿里云买的轻应用主机,一年 99,域名一年 20(貌似以后续费一年 32),总计一年:119 ¥
总结 为何写作:主要用记录技术笔记,记录看过的东西,分享想分享的,营造技术影响力。有一句口号:爱我所爱,想我所想,写我所写。
Prompt 学习笔记
生成 Prompt 最好的方法是让 AI 自己生成。 我们可以让他按某个框架生成一份,然后在此基础上调优。
推荐几个框架
ICIO
假设我们希望让模型总结一篇关于机器学习应用的文章,Prompt 的设计可以如下:
- Instruction(指令):请提供一段关于本文内容的简洁总结。
- Context(背景):本文讨论了机器学习在医疗诊断中的应用,并分析了不同算法的优劣。
- Input(输入):输入的文章内容,包括关于医疗诊断的机器学习应用的信息。
- Output(输出):请将总结控制在 3-4 句话内,简洁明了。
CRISP
CRISP 是一个围绕 Prompt 精度和一致性而设计的框架,分别从上下文(Context)、角色(Role)、输入(Input)、结构(Structure)和目标(Purpose)五个方面来优化 Prompt。
Context(上下文):为模型提供任务背景,以确保它理解任务的整体情境。
Role(角色):在 Prompt 中指定模型的角色,帮助它更好地适应输出风格。例如,让模型扮演“教授”、“客户服务代表”或“数据分析师”。
Input(输入):模型需要处理的主要信息或材料。
Structure(结构):输出的组织方式或逻辑结构,确保模型生成条理清晰的内容。
Purpose(目标):明确任务的最终目标或期望效果,例如“解释”、“推荐”或“分析”。
示例:上下文:关于区块链的技术介绍。
角色:作为一个区块链专家。
输入:给定的区块链介绍文本。
结构:逐条说明。
目标:让普通人理解区块链的基本概念。
LLM 模型测试
hugging face 下载模型
首先在 poweshell 下设置代理,该方式只在 session 中生效
1 | $env:HTTP_PROXY="http://username:password@xxxx.xxxx.xxxx.xxxx:3030" |
下载指定模型,如果是 llama,请先登录,获取授权
1 | huggingface-cli login |
llama.cpp
构建 llama.cpp 环境
1 | git clone https://github.com/ggerganov/llama.cpp.git |
验证依赖安装是否正确
1 | python convert_hf_to_gguf.py |
如上即为正常。
不符合Windows 11硬件标准如何升级Windows 11
1、通过以下地址,从 GitHub 相关页面的“Asset”中,下载 Source code 文件;
下载地址:https://github.com/abbodi1406/offlineinsiderenroll/releases
2、解压压缩包,从中找到“OfflineInsiderEnroll.cmd”,右键点击使用管理员权限运行;
3、在命令行窗口中,选择“1”Dev 通道,并按下回车键确认;
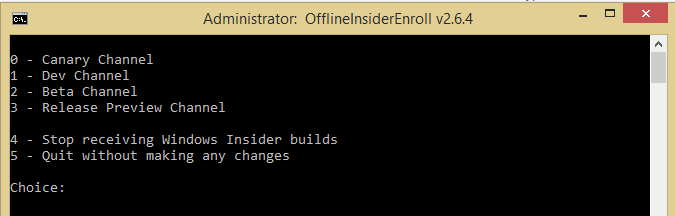
4、重启电脑,随后到设置面板中的 Windows Update 检查更新,应该就可以收到 Windows 11 预览版的推送了。
杜架的记录与分享(012期)
杜架的记录与分享,记录与思考有价值的信息,主要包含:碎片化思考,阅读笔记分享,软件分享,内容记录等。内容主题有极大的个人喜好偏向,爱我所爱,想我所想,写我所写。
中秋节去了趟平遥和祁县,看了乔家大院和平遥古城,国庆节又重游故宫和颐和园。颇有感慨,乔家大院的精致雕刻和平遥古城的古朴风貌,让人仿佛穿越回了几百年前的时光。再访故宫,依然能感受到皇城的庄严和辉煌,而颐和园的山水庭院则展现了皇家园林的诗意与优雅。
时光荏苒,世事变迁。王朝更替,富商凋落。曾经辉煌一时的宫殿和宅邸,如今成了历史的遗迹,供后人凭吊和瞻仰。当年繁华的街市与商铺早已人去楼空,取而代之的是游客的匆匆脚步和拍照的快门声。那些承载着无数故事的古老建筑,虽然风雨侵蚀,却依然静静伫立,似乎在默默诉说着它们曾经的繁荣与兴衰。世事无常,但历史留下的痕迹却让我们在变迁中找到永恒的回响。
乔家经过四代的努力才逐渐发展成为富商世家,感慨万千。
你一定好奇古人食谱啥样,给大家看一看乔家,日升昌,平遥县令的伙食,山西土老帽,手里拎的可是金元宝。


