AI Agent
当前关于 Agent 工程的两大业内共识:
- 使用文件系统作为上下文(如使用文件保存 Agent 长期记忆,如 OpenClaw 的 SOUL.md/TOOLS.md/MEMORY.md 等)
- 编程是解决通用问题的一种普适方法(AI 更擅长使用代码解决问题:问题->生成代码->执行代码->Again->直到问题解决)

常用设计模式
ReAct 模式
ReAct 智能体的运作基于一个循环过程(不断迭代更新),包括以下三个步骤:
- 推理(Reasoning):依赖 LLM,分析当前任务状态,生产内部推理,决定下一步行动,核心思想是 CoT(Chain of Thought)
- 执行(Acting):根据上一步的推理结果,执行具体的操作,例如查询信息或调用外部工具(Function Tool,MCP, Shell 命令,代码执行等),具体依赖宿主机的执行环境与应用场景
- 观察(Observation):观察行动的结果,将反馈用于下一轮的思考;或者观察到已经判断是最终的答案,则整理输出结果
核心思想是交替进行“推理 → 行动 → 观察”。
典型流程:
- Thought(思考)
- Action(调用工具)
- Observation(获取结果)
适用于:
- 需要外部工具(搜索、数据库、API)
- 非一次性可解问题
特点:强化可解释性,但推理链较长、成本高。
**实现原理: **
思考和 Action 是通过 prompt 实现的,以下为 ReAct 的一个 prompt
1 | Answer the following questions as best you can. You have access to the following tools: |
案例:特斯拉股票多少钱?
1 | Thought: 需要获取特斯拉股价 |
Plan-and-Execute 模式
核心思想:让 LLM 先制定完整的分步计划,再按步骤执行,而非边做边想(ReAct)
结构:
- Planner(生成步骤)
- Executor(执行每一步)
适用于:
- 长任务(如写报告、复杂自动化)
- 需要减少推理重复
优点:比 ReAct 更稳定、更省 token
缺点:计划可能不完备,需要重规划机制
**实现原理: **
Plan
1 | You are a planner. |
模型输出:
1 | 1. Get Tesla stock price |
Executor 的实现原理
Executor 内部就是一个标准的 ReAct Agent,每一个 step 都是一次独立的 ReAct 调用。
输入步骤后被包装成:
1 | "Please execute the following step: Get Tesla stock price" |
然后进入 ReAct 循环
1 | Thought → Action → Observation → Final Answer |
Reflection
Reflection(反思模式)本质是在普通 Agent 流程里加入:
先做 → 再批判自己 → 再修正
它解决的问题是:
普通 Agent 往往“一次生成就交卷”;
Reflection 让 Agent 像 reviewer 一样自己挑错。
一、最基本结构
最经典流程:
1 | Generate |
什么时候用 Reflection?
适合:
- 写作(报告 / 论文 / 内容)
- 代码生成
- 推理题(需要严谨性)
- 高质量输出场景
不适合:
- 简单问答(成本太高)
- 实时性要求高的系统
其他模式
- Route
- Tool use
- RAG
Agent 工程经验
每一个 Agent 中必包含 Agent Loop,本质就是一个 while 循环。
Agent 典型的工作流程如下:
1 | 初始上下文(系统提示词+用户请求) |
参考文档:
- 深度解析 Claude Code 在 Prompt / Context / Harness 的设计与实践
- 深度解析 OpenClaw 在 Prompt / Context / Harness 三个维度中的设计哲学与实践
易点天下 Agent 经验
分享一些关于易点天下经验
运行时注入
易点天下借鉴了 Hook 化的主动推送思路,在 Agent 生命周期的关键节点内置了三类检索钩子:
- UserMessage 钩子:在用户提问进入 Agent Loop 之前,先做意图过滤与关键词 / 语义双路召回,将相关记忆分层注入到 System Prompt;
- PreToolUse 钩子:在写文件、改配置等敏感工具调用之前,按精确资源 ID 匹配历史变更记录与已知风险,避免 Agent 重复踩坑;
- ErrorSignal 钩子:一旦检测到错误关键字(timeout、OOM、ImagePullBackOff 等),自动按 bugs/errors 维度拉取历史解法并分层注入。
渐进式注入与分层内容
- 三级内容分层:每条知识都会被预先生成 L0/L1/L2 三种”分辨率”——L0 Abstract 约 100 tokens 的一句话摘要,L1 Overview 约 300 tokens 的详细要点,L2 Full 则是完整 Markdown 全文;
- 按相关度动态选档:检索命中后,相关度 score > 0.8 注入 L1、score ≤ 0.8 降级为 L0、用户或 Agent 主动 Read 时才展开 L2,单次注入 Token 稳定压在 100–300 的小窗口内;
- 短会话直通,长会话采样:当整段会话字符数在预算之内时直通不压缩,零信息损失;一旦超预算,优先截断单条 assistantText,而不是整段丢弃问答对,保住推理链条的完整性;
- 硬预算 + 软降级:每条链路都设有明确的性能预算(如 UserMessage 注入 3 秒、PreToolUse 注入 100 毫秒内完成),超时即走降级路径,宁可少注入也不阻塞主流程。
渐进式工具加载
初始态仅激活 list_pods 等核心工具,其余长尾工具仅在 Prompt 中保留极简描述;当模型推理需要时,通过内部的 tool_search 能力按需动态唤醒并加载对应工具。
压缩续接
系统在窗口接近阈值时会触发 PreCompact 钩子:将既有对话按”问题—行动—观察—结论”的结构化摘要格式进行压缩,生成 { overview, steps, todos } 三段式的会话摘要,并在下一轮启动时作为 Warm 层(最近 10 次会话摘要,FIFO 淘汰)注入。
Prompt Engineering
提示词主要承担两个任务:一是明确模型的角色和行为边界,二是约束输出的格式和风格
Prompt 通常包含:
- 角色(Role)
- 任务(Task)
- 上下文(Context)
- 约束(Constraints)
- 输出格式(Format)
- 示例(Examples)
- 推理方式(Reasoning)
一个高质量 Prompt 的目标:
- 降低歧义
- 限制输出空间
- 提高稳定性
- 提高可复现性
- 降低 hallucination(幻觉)
一个优秀 Prompt 示例:
1 | 你是一名资深数据分析师。 |
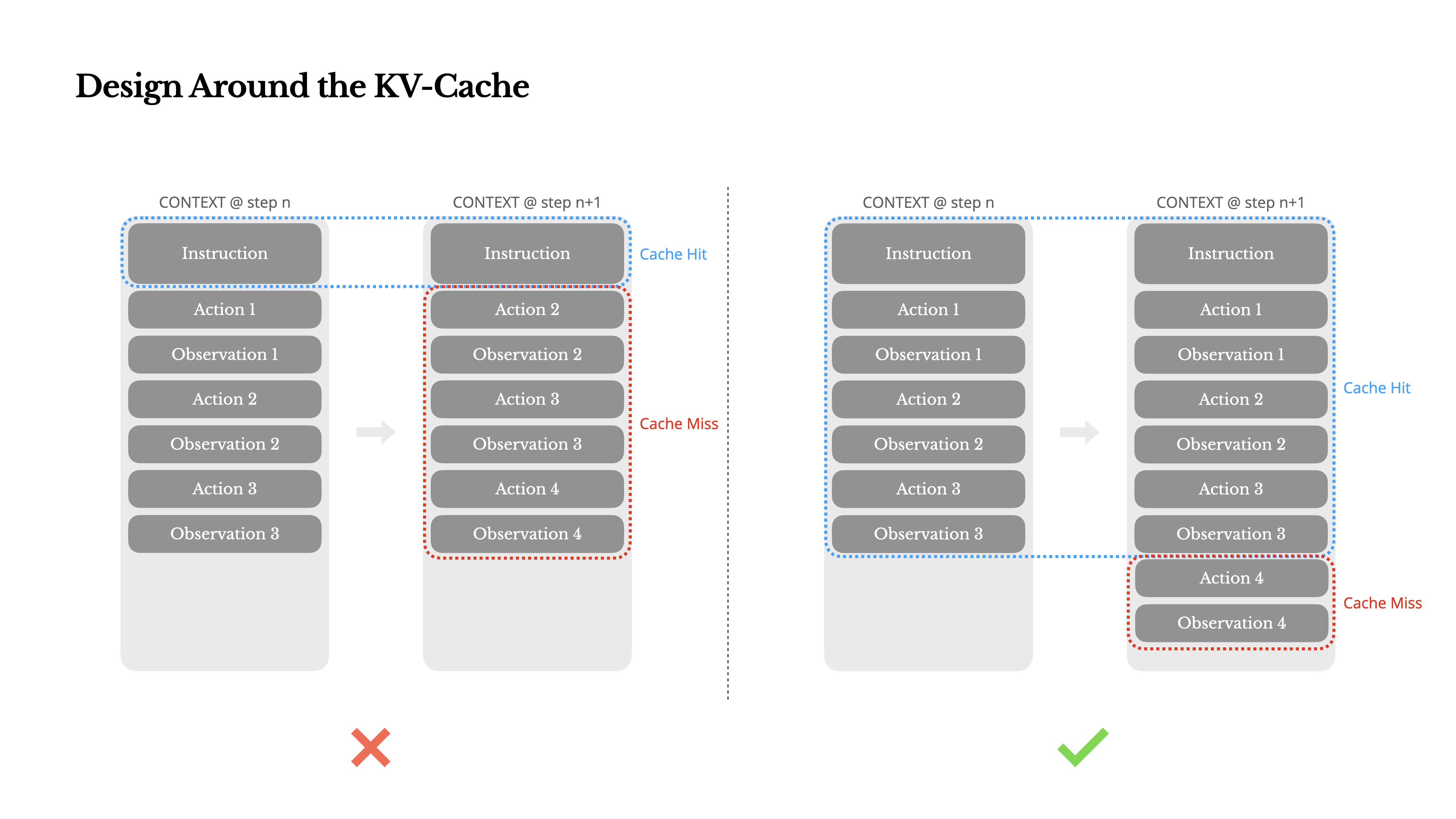
Prompt Caching 减少重复开销
如果当前请求的输入前缀和之前某次请求完全一致,这部分 KV 就不需要重新计算,直接从缓存读取,这就是 Prompt Caching 的底层原理。
命中的前提是精确前缀匹配,不是内容相似就能触发,任何一个 token 不同都会破坏匹配,所以缓存友好的设计核心是稳定性,系统提示、工具定义、长文档这类在多轮请求里基本不变的内容天然适合缓存,动态信息(当前时间、用户输入、工具调用结果)放在后面,不影响前缀的稳定性。
1 | Claude Code 的 Prompt 顺序: |
Context Engineering
上下文工程则是设计如何组织、管理和优化这些上下文信息以提升 Agent 的决策质量和效率。

1 | Context = System Prompt |
解决上下文工作最常用的办法是按信息的使用频率和稳定性分层管理,每层只放自己该放的东西:
- 常驻层:身份定义、项目约定、绝对禁止项,每次会话都必须成立的内容,保持短、硬、可执行
- 按需加载:Skills 和领域知识,描述符常驻,完整内容触发时再注入,不用的不占位置
- 运行时注入:当前时间、渠道 ID、用户偏好等动态信息,每轮按需拼入
- 记忆层:跨会话经验写入 MEMORY.md,不直接进系统提示,需要时才读取
- 系统层:Hooks 或代码规则处理确定性逻辑,完全不进上下文
别把确定性逻辑放进上下文,凡是可以通过 Hooks、代码规则或工具约束表达的内容,都应交给外部系统处理,而不是让模型反复读取。
记忆(Memory)系统设计
- 上下文窗口,工作记忆:当前任务所需的最小信息,token 有限,得主动管理
- Skills,程序性记忆:怎么做某件事,操作流程、领域规范,按需加载不默认常驻
- JSONL 会话历史,情景记忆:发生了什么,磁盘持久化,支持跨会话检索
- MEMORY.md,语义记忆:Agent 主动写入认为重要的事实,每次启动时注入系统提示
三种常见压缩策略
| 策略 | 成本 | 丢什么 | 适用场景 |
|---|---|---|---|
| 滑动窗口 | 极低 | 早期上下文 | 简短对话 |
| LLM 摘要 | 中 | 细节,保留决策 | 长任务、含关键决策 |
| 工具结果替换 | 极低 | 工具原始输出 | 工具调用密集型 |
Harness Engineering
Harness Engineering 是一整套让 AI 在工程里持续,稳定的产出正确结果的工程系统。
借用 AgentScope 定义的 Harness 工程化-—— 长期运行、复杂任务的工程底座
| 功能 | 核心能力 | 关键特点 |
|---|---|---|
| 1. 自进化与技能仓库(Skill Repository) | 将成功经验沉淀为可复用技能。 | - 成功模式自动保存为 Markdown 技能文件。 - 存储于 workspace/skills/。- 后续任务按需加载,实现跨会话 Know-how 积累。 |
| 2. 分层记忆管理(Hierarchical Memory) | 多层次管理长期与短期记忆。 | - 三层记忆: ① 当前对话 Context; ② Agent 自维护 MEMORY.md;③ 磁盘事实流水账。 - 自动压缩 Prompt。 - 提供 memory_* 工具进行显式回忆。 |
| 3. 子智能体(Subagents) | 将复杂任务拆分并并行处理。 | - 使用 Markdown 定义子 Agent。 - 支持 agent_spawn 和 agent_send。- 可同步执行或后台运行。 - 后台完成后主动通过 system-reminder 推送结果,无需轮询。 |
| 4. 上下文自动管理(Context Management) | 控制上下文长度并保留关键信息。 | - 自动结构化压缩:保留目标、状态、关键发现、下一步。 - 超大工具输出落盘,仅保留引用。 - Context Overflow 自动恢复与重试。 |
| 5. 复杂任务规划(Plan Mode) | 将长期任务的规划与执行解耦。 | - 只读规划模式。 - 长任务拆解为多个步骤。 - 计划文件保存至 workspace/plans/。- 后续执行依据计划推进。 |
| 6. Workspace 工程底座(Workspace Foundation) | 提供统一的持久化运行环境。 | - 人格配置(Persona)。 - 知识库(Knowledge)。 - 技能库(Skills)。 - 子 Agent 定义。 - 会话日志。 - 全部以 Markdown/JSON 持久化,并在每轮自动注入 System Prompt。 |
Claude Code 经验
记忆系统分为六层:
- Managed Policy(组织级策略):企业或团队层面的统一规范
- Project CLAUDE.md(项目配置):当前项目的特定指令和上下文
- User Preferences(用户偏好):个人层面的习惯和偏好设置
- Auto-Memory(自动学习模式):Agent 从历史交互中学到的用户模式
- Session(会话上下文):当前会话的临时信息
- Sub-Agent Memory(子 Agent 记忆):各子 Agent 独立维护的专项记忆
提示词设计
固定不变:
- 身份和角色:”你是一个交互式代理,帮助用户完成软件工程任务”
- 系统指令:Markdown 渲染规则、工具权限模式说明、注入攻击防御
- 编码哲学:不要过度工程、不要提前抽象、三行相似代码好过一个过早抽象
- 工具使用指南:优先用 Read 不用 cat、优先用 Edit 不用 sed、优先用 Glob 不用 find
- 语气风格:简洁直接、不用 emoji、一句能说清的别用三句
每轮刷新:
- 环境信息:当前目录、git 分支、最近几条提交、平台信息、模型知识截止日期
- 用户上下文:CLAUDE.md 的内容、MEMORY.md 的持久记忆
- MCP 指令:已连接的 MCP 服务器提供的工具描述
- 技能列表:当前可用的斜杠命令
- Hook 指令:用户配置的钩子说明
- 输出风格:基于用户配置的格式偏好
工具列表是按字母顺序排列的,保持 prompt cache 的稳定性。固定不变的在前面,动态更新放在后面。
四级上下文压缩管道
1 | Snip Compact → Micro Compact → Context Collapse → Auto Compact |
- Level 1 — Snip Compact:基于标记的历史裁剪。在消息流中找到 snip 边界标记,移除标记之前的消息。最轻量,无需 API 调用。
- Level 2 — Micro Compact:缓存编辑压缩。利用 API 的 cache editing 能力,在不破坏整体缓存的情况下删除特定工具调用的结果(4 级 BP 标记)。
- Level 3 — Context Collapse:上下文折叠。将多轮工具调用结果折叠为摘要,但保留结构。这是一个读时投影——折叠视图在每次发送前重新计算,原始消息仍然保存在 REPL 的完整历史中。
- Level 4 — Auto Compact:全量摘要压缩。当上下文接近窗口限制时,使用 LLM 生成对话摘要替换历史消息。这是最重的操作,但也是最后的防线。