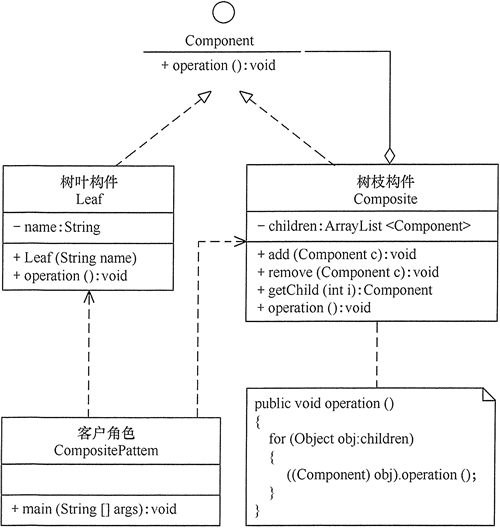
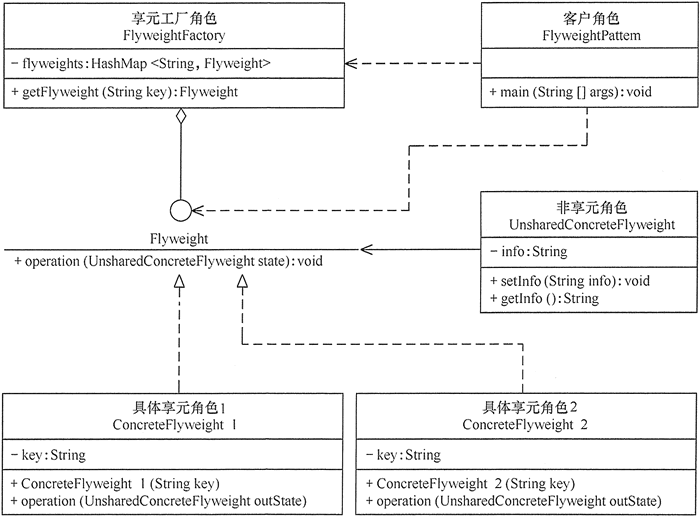
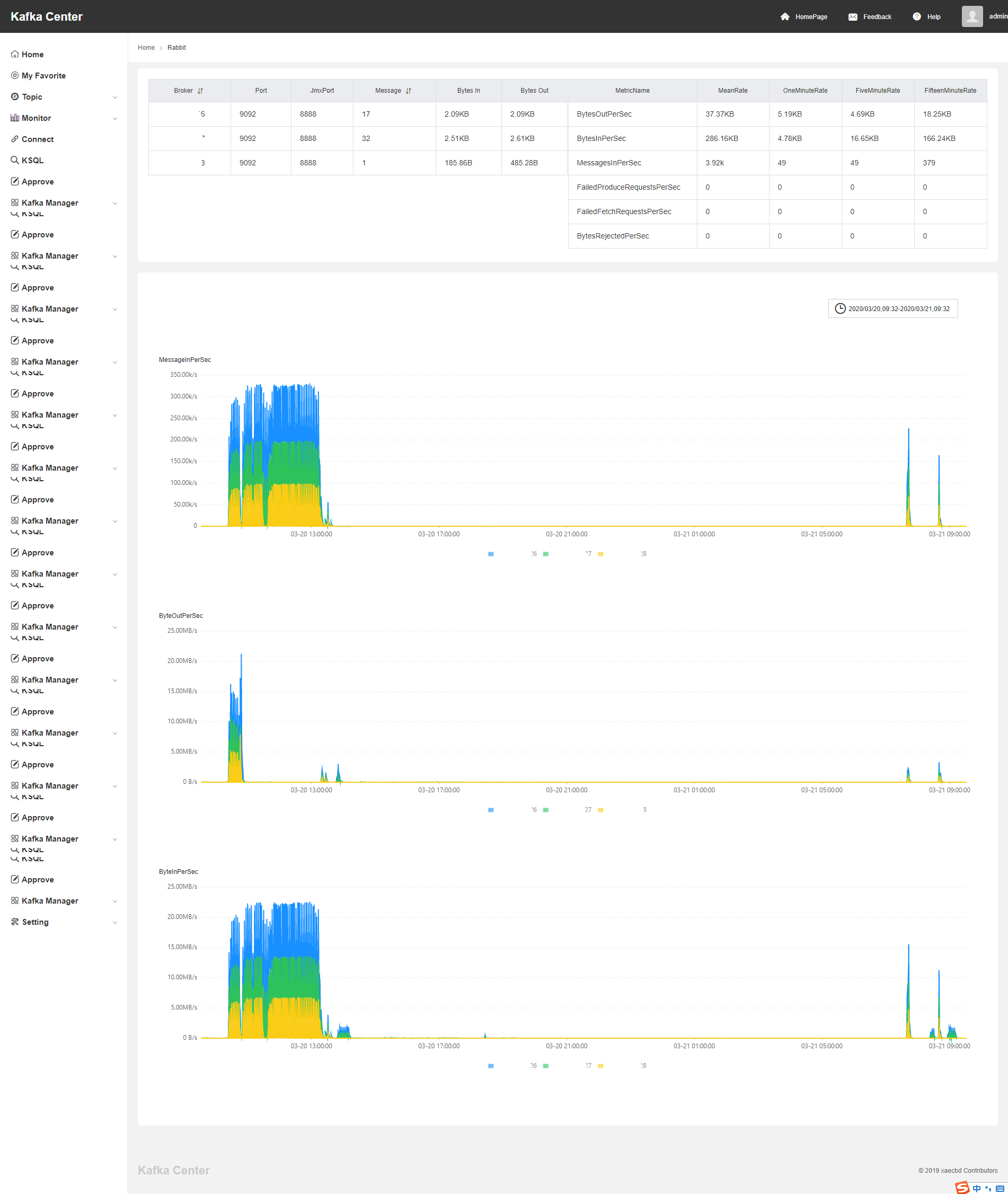
interface Factory{ void produce(); } class CarFactory implements Factory{ @Override public void produce() { System.out.println("汽车工程生产"); new Bus(); } } class SuperCarFactory implements Factory{ @Override public void produce() { System.out.println("超跑汽车工程生产"); new SuperCar(); } } interface Car{ void show(); }
class Bus implements Car{ @Override public void show() { System.out.println("公共汽车。。。"); } } class SuperCar implements Car{ @Override public void show() { System.out.println("超跑。。。"); } }
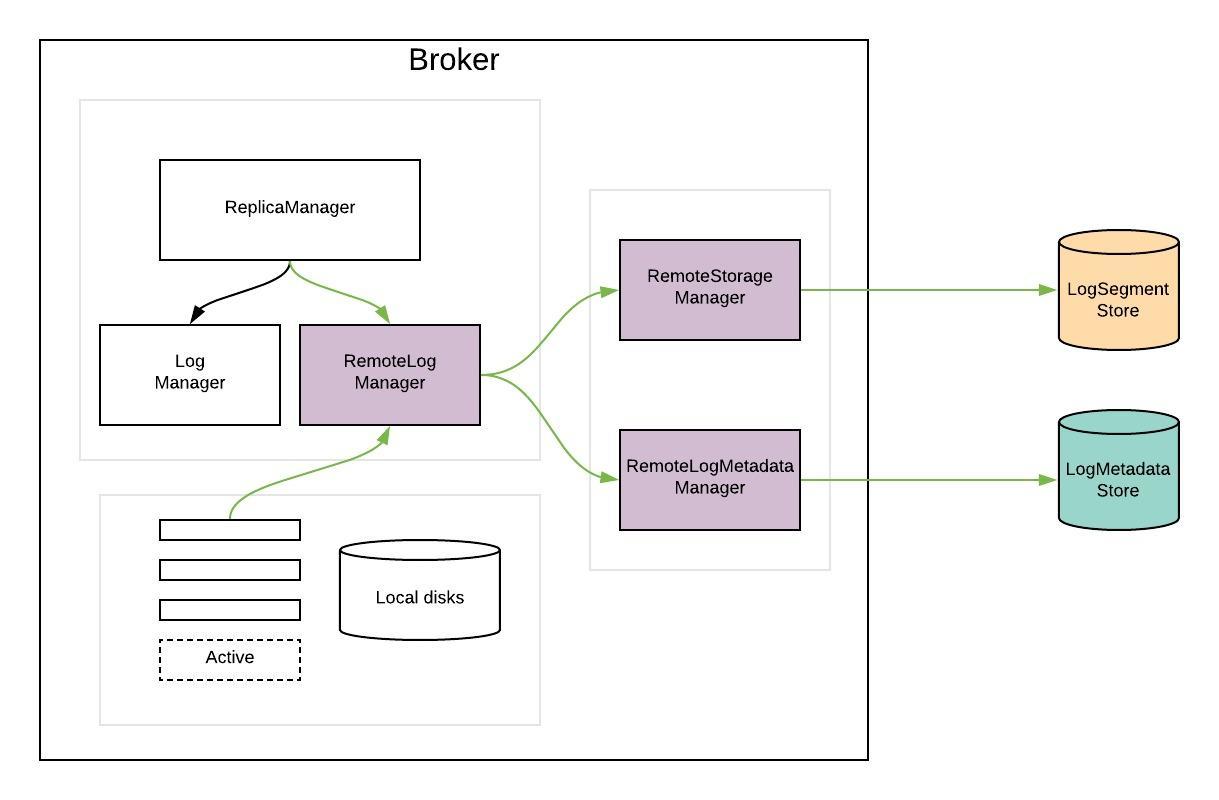
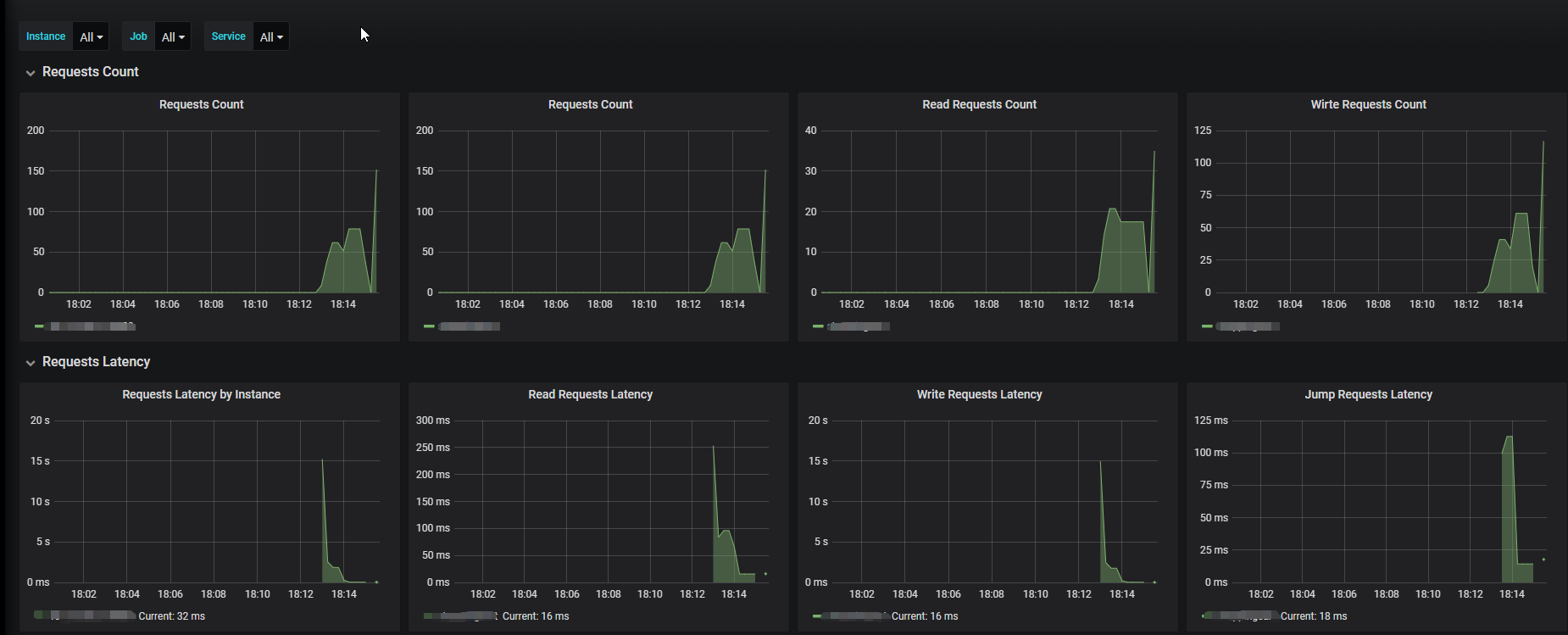
global: scrape_interval: 15s # By default, scrape targets every 15 seconds. evaluation_interval: 15s # By default, scrape targets every 15 seconds. # scrape_timeout is set to the global default (10s). # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first.rules" # - "second.rules"
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'demo_platform'
# Override the global default and scrape targets from this job every 5 seconds. scrape_interval: 5s
metrics_path: '/actuator/prometheus' # scheme defaults to 'http'.
static_configs: - targets: ['127.0.0.1:8080']
搭建grafana
1
docker run -d -p 3000:3000 --name grafana grafana/grafana:6.5.0
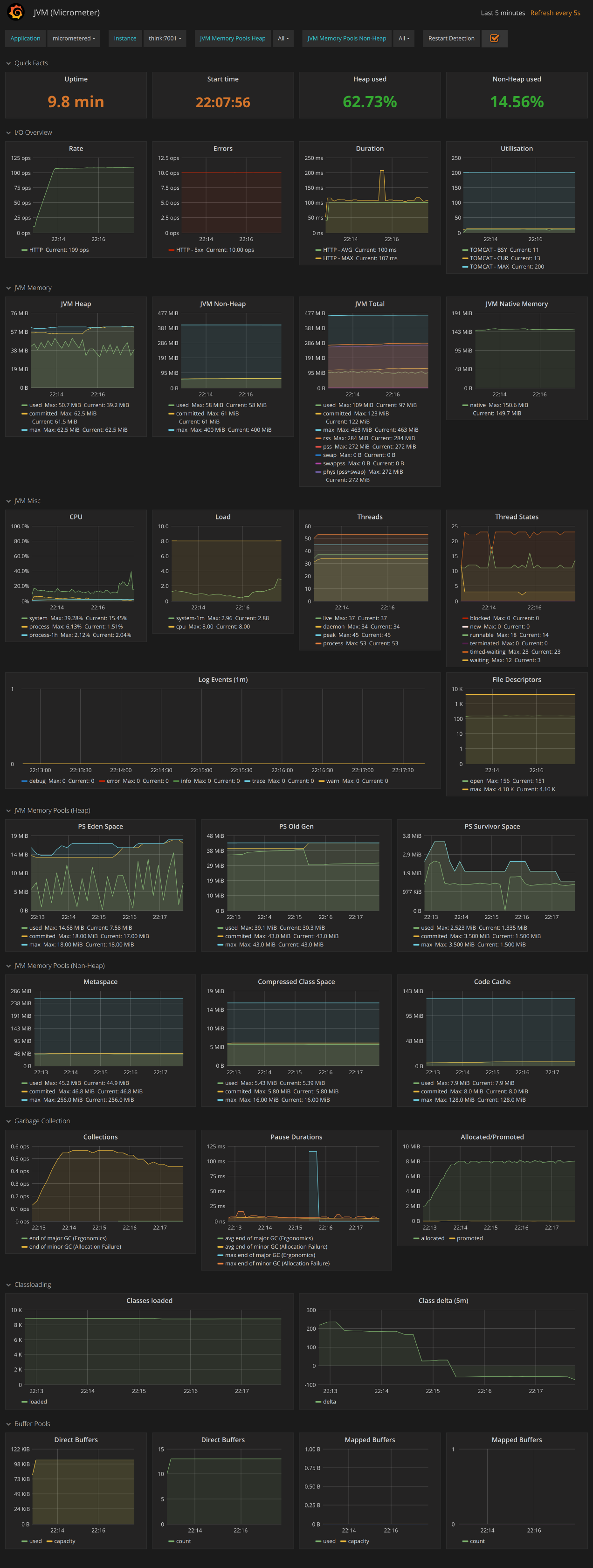
Micrometer简介
Micrometer(译:千分尺) Micrometer provides a simple facade over the instrumentation clients for the most popular monitoring systems. 翻译过来大概就它提供一个门面,类似SLF4j。支持将数据写入到很多监控系统,不过我谷歌下来,很多都是后端接入的是Prometheus.
Micrometer提供了与供应商无关的接口,包括 timers(计时器), gauges(量规), counters(计数器), distribution summaries(分布式摘要), long task timers(长任务定时器)。它具有维度数据模型,当与维度监视系统结合使用时,可以高效地访问特定的命名度量,并能够跨维度深入研究。
尝试并了解不同的技术堆栈:如果您想成为一名更好的架构师,我认为这是最重要的活动。试用(新)技术堆栈,并了解它们的兴衰。不同或新技术具有不同的设计方面和模式。您很可能从翻阅抽象幻灯片中不会学到任何东西,而是自己尝试一下,并感到痛苦或缓解。架构师不仅应该具有广泛的知识,而且在某些领域还应具有深厚的知识。掌握所有技术堆栈并不重要,但要对您所在地区的最重要知识有深入的了解。另外,请尝试不使用您所处领域的技术,例如,如果您深入 SAP R / 3,则还应该尝试 JavaScript,反之亦然。尽管如此,双方仍会对 SAP S / 4 Hana 的最新进展感到惊讶。例如,您可以自己尝试,然后免费在 openSAP 上课程。好奇并尝试新事物。还可以尝试一些您几年前不喜欢的东西。
重构不是邪恶的:如果找不到更好的主意,那么从更复杂的解决方案开始是完全可以的。如果解决方案遇到麻烦,您可以稍后重新考虑解决方案并应用您的学习。重构不是邪恶的。但是在开始重构之前,请记住要进行以下工作:(1)进行足够的自动化测试,以确保系统的正确功能;(2)从利益相关者获取支持。要了解有关重构的更多信息,建议阅读“Refactoring. Improving the Design of Existing Code”,作者是 Martin Fowler。
了解基本的项目管理原则:作为架构师或首席开发人员,经常会要求您提供估计以实现您的想法:多长时间,花费多少,多少人,哪些技能等?当然,如果您打算引入新的工具或框架,则需要为此类“管理”问题提供答案。最初,您应该能够进行粗略的估算,例如几天,几个月或几年。并且不要忘记,这不仅涉及实现,还有更多活动需要考虑,例如需求工程,测试和修复错误。因此,您应该了解所使用的软件开发过程的活动。您可以应用以获得更好的估计的一件事是使用过去的数据并从中得出您的预测。如果您没有过去的数据,也可以尝试使用 Barry W. Boehm 的 COCOMO 之类的方法。如果您部署在敏捷项目中,请学习如何进行估算和正确计划:Mike Cohn 撰写的《敏捷估算和规划》一书对此领域提供了扎实的概述。
寻找盟友:很难独自建立或执行您的想法,甚至是不可能的。尝试找到可以支持和说服他人的盟友。使用您的网络。如果还没有,请立即开始构建。您可以从与(思想开放的)同事讨论您的想法开始。如果他们喜欢它,或者至少喜欢它的一部分,那么如果别人提出来,他们很可能会支持您的想法(“ X 的想法很有趣。”)。如果他们不喜欢,问为什么:也许您错过了什么?还是您的故事不够令人信服?下一步是找到具有决定权的盟友。要求开放的讨论。如果您担心讨论,请记住,有时您需要离开舒适区。