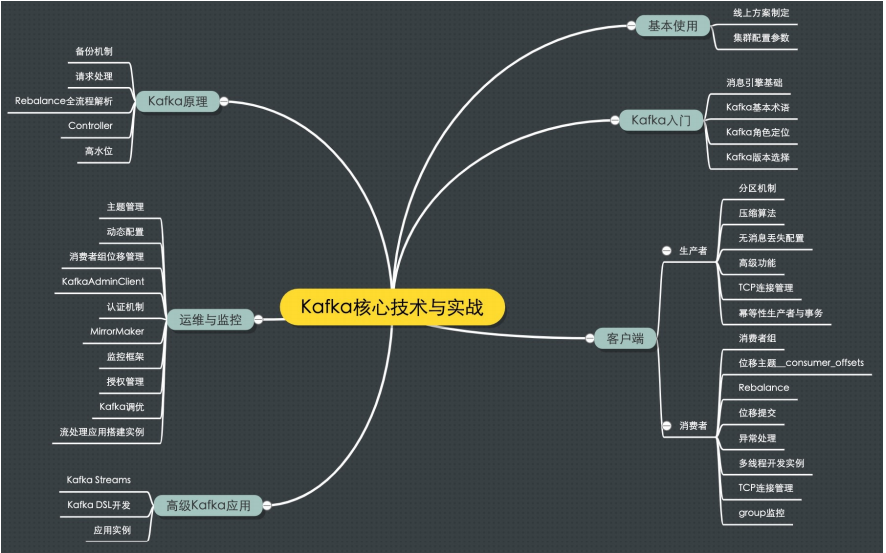
设计模式总结 创建型 创建型模式主要解决对象的创建问题,封装复杂的创建过程,解耦对象的创
单例模式 ⽤来创建全局唯⼀的对象。
⼯⼚模式 ⽤来创建不同但是相关类型的对象(继承同⼀⽗类或者接⼝的⼀组⼦类),由给定的参数来决定创建哪种类型的对象。
建造者模式 是⽤来创建复杂对象,可以通过设置不同的可选参数,“定制化”地创建不同的对象。
原型模式 针对创建成本⽐较⼤的对象,利⽤对已有对象进⾏复制的⽅式进⾏创建,以达到节省创建时间的⽬的。
单例模式 懒汉
1 2 3 4 5 6 7 8 9 10 11 12 13 public class LazySingleton { private static volatile LazySingleton instance = null; private LazySingleton() { } public synchronized LazySingleton getInstance() { if (instance == null) { instance = new LazySingleton(); } return instance; } }
饿汉
1 2 3 4 5 6 7 8 9 10 public class HungrySingleton { private static HungrySingleton instance = new HungrySingleton(); private HungrySingleton() { } public static HungrySingleton getInstance() { return instance; } }
静态内部类
1 2 3 4 5 6 7 8 9 10 11 12 public class StaticInnerClassSingleton { private StaticInnerClassSingleton() { } public static StaticInnerClassSingleton getInstance() { return LazyHolder.innerClassSingleton; } private static class LazyHolder { private static StaticInnerClassSingleton innerClassSingleton = new StaticInnerClassSingleton(); } }
枚举类
1 2 3 4 5 6 7 public enum SingletonEmum { INSTANCE; public void doSomething() { System.out.println("value"); } }
工厂模式 工厂方法与抽象工厂的区别是:抽象工厂可以在一个工厂内生产多个商品,工厂方法只能生产一个
主要角色 :
抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法 newProduct() 来创建产品。
具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一一对应。
工厂方法模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 interface Factory{ void produce(); } class CarFactory implements Factory{ @Override public void produce() { System.out.println("汽车工程生产"); new Bus(); } } class SuperCarFactory implements Factory{ @Override public void produce() { System.out.println("超跑汽车工程生产"); new SuperCar(); } } interface Car{ void show(); } class Bus implements Car{ @Override public void show() { System.out.println("公共汽车。。。"); } } class SuperCar implements Car{ @Override public void show() { System.out.println("超跑。。。"); } }
抽象工厂模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 interface Factory { Product produceEngine(); Product produceTyre(); } class CarFactory implements Factory { @Override public Product produceEngine() { System.out.println("汽车工厂:生产发动机"); return new Engine(); } @Override public Product produceTyre() { System.out.println("汽车工厂:生产发轮胎"); return new Tyre(); } } class SuperCarFactory implements Factory { @Override public Product produceEngine() { System.out.println("超跑汽车工厂:生产发动机"); return new Engine(); } @Override public Product produceTyre() { System.out.println("超跑汽车工厂:生产发轮胎"); return new Tyre(); } } interface Product { void show(); } class Tyre implements Product { @Override public void show() { System.out.println("轮胎。。。"); } } class Engine implements Product { @Override public void show() { System.out.println("发动机。。。"); } }
建造者模式 适用场景
参数很多的bean初始化,可以对参数的强约束。
实现
使用静态内部类实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class Bean { private String a; private String b; private String c; private String d; private Bean(Builder builder) { a = builder.a; b = builder.b; c = builder.c; d = builder.d; } static class Builder { private String a; private String b; private String c; private String d; public Builder a(String a) { this.a = a; return this; } public Builder b(String b) { this.b = b; return this; } public Builder c(String c) { this.c = c; return this; } public Builder d(String d) { this.d = d; return this; } public Bean build() { return new Bean(this); } } }
使用:
1 Bean bean = new Bean.Builder().a("a").b("b").c("c").build();
原型模式 原型模式的克隆分为浅克隆和深克隆,Java 中的 Object 类提供了浅克隆的 clone() 方法,具体原型类只要实现 Cloneable 接口就可实现对象的浅克隆
结构型 代理模式 主要角色 :
抽象主题(Subject)类:通过接口或抽象类声明真实主题和代理对象实现的业务方法。
真实主题(Real Subject)类:实现了抽象主题中的具体业务,是代理对象所代表的真实对象,是最终要引用的对象。
代理(Proxy)类:提供了与真实主题相同的接口,其内部含有对真实主题的引用,它可以访问、控制或扩展真实主题的功能。
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public interface Subject { void request(); } public class ConcreteSubject implements Subject { @Override public void request() { System.out.println("执行请求"); } } public class Proxy implements Subject { private Subject subject = new ConcreteSubject(); public void preRequest() { System.out.println("pre"); } @Override public void request() { preRequest(); subject.request(); afterRequest(); } public void afterRequest() { System.out.println("after"); } public static void main(String[] args) { Proxy proxy =new Proxy(); proxy.request(); } }
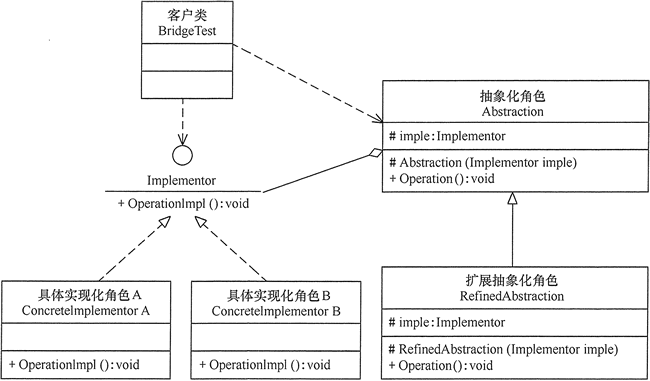
桥接模式 定义 桥接(Bridge)模式:将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
抽象化和实现化之间使用关联关系(组合或者聚合关系)而不是继承关系,从而使两者可以相对独立地变化,这就是桥接模式的用意。
适用场景:
当一个类存在两个独立变化的维度,且这两个维度都需要进行扩展时。例如包有钱包,手提包,又有颜色(黄、红、蓝)
实现 主要角色
抽象化(Abstraction)角色:定义抽象类,并包含一个对实现化对象的引用。
扩展抽象化(Refined Abstraction)角色:是抽象化角色的子类,实现父类中的业务方法,并通过组合关系调用实现化角色中的业务方法。
实现化(Implementor)角色:定义实现化角色的接口,供扩展抽象化角色调用。
具体实现化(Concrete Implementor)角色:给出实现化角色接口的具体实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 abstract class Bag { Color color; public void setColor(Color color) { this.color = color; } abstract void echoName(); } class HandBag extends Bag { @Override void echoName() { System.out.println(color.getColor() + "的挎包"); } } class Wallet extends Bag { @Override void echoName() { System.out.println(color.getColor() + "的钱包"); } } interface Color { String getColor(); } class Yellow implements Color{ @Override public String getColor() { return "黄"; } } class Red implements Color{ @Override public String getColor() { return "红"; } }
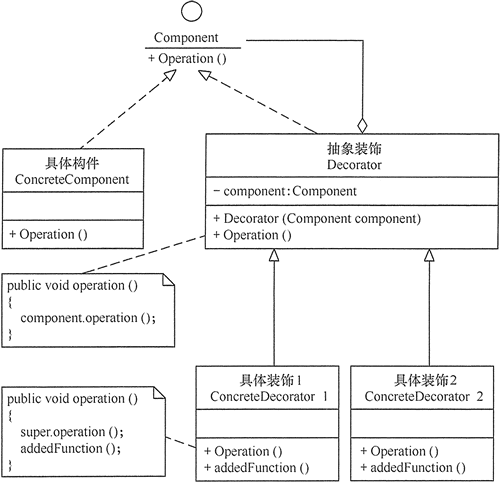
装饰器模式 定义 装饰(Decorator)模式:指在不改变现有对象结构的情况下,动态地给该对象增加一些职责(即增加其额外功能)的模式
jdk io就使用了装饰器模式,例如,InputStream 的子类 FilterInputStream,OutputStream 的子类 FilterOutputStream,Reader 的子类 BufferedReader 以及 FilterReader,还有 Writer 的子类 BufferedWriter、FilterWriter 以及 PrintWriter 等,它们都是抽象装饰类。
1 2 BufferedReader in=new BufferedReader(new FileReader("filename.txtn)); String s=in.readLine();
应用场景
当需要通过对现有的一组基本功能进行排列组合而产生非常多的功能时,采用继承关系很难实现,而采用装饰模式却很好实现。
实现 主要角色
抽象构件(Component)角色:定义一个抽象接口以规范准备接收附加责任的对象。
具体构件(Concrete Component)角色:实现抽象构件,通过装饰角色为其添加一些职责。
抽象装饰(Decorator)角色:继承抽象构件,并包含具体构件的实例,可以通过其子类扩展具体构件的功能。
具体装饰(ConcreteDecorator)角色:实现抽象装饰的相关方法,并给具体构件对象添加附加的责任
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 public interface Component { void operation(); } public class ConcreteComponent implements Component { @Override public void operation() { System.out.println("Concrete Component operation"); } } public class Decorator implements Component{ Component component; public Decorator(Component component){ this.component = component; } @Override public void operation() { component.operation(); } } public class ConcreteDecoratorA extends Decorator { public ConcreteDecoratorA(Component component) { super(component); } public void addFunction(){ System.out.println("add a function"); } @Override public void operation() { addFunction(); super.operation(); } } public class ConcreteDecoratorB extends Decorator { public ConcreteDecoratorB(Component component) { super(component); } public void addFunction(){ System.out.println("add b function"); } @Override public void operation() { addFunction(); super.operation(); } } public static void main(String[] args) { Component component = new ConcreteComponent(); Decorator decorator = new ConcreteDecoratorA(component); decorator.operation(); }
这样做的好处是可以通过组合形成更多的构件功能,例如如上代码,可以组装出具有a功能的ConcreteComponent,具有b功能的ConcreteComponent,或者新增一个NewConcreteComponent。进而可以组装出具有a功能的NewConcreteComponent
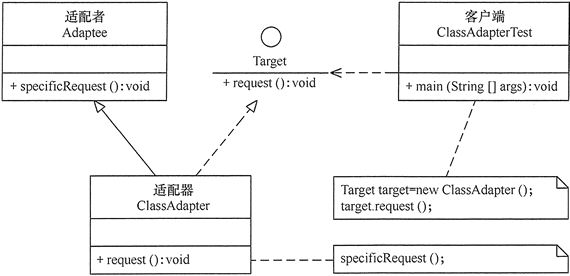
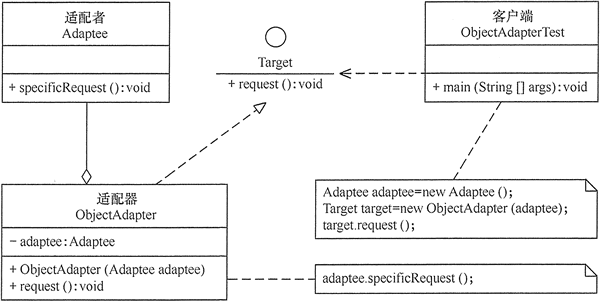
适配器模式 定义 适配器模式(Adapter):将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。适配器模式分为类结构型模式和对象结构型模式两种,前者类之间的耦合度比后者高,且要求程序员了解现有组件库中的相关组件的内部结构,所以应用相对较少些。
实现 主要角色
目标(Target)接口:当前系统业务所期待的接口,它可以是抽象类或接口。
适配者(Adaptee)类:它是被访问和适配的现存组件库中的组件接口。
适配器(Adapter)类:它是一个转换器,通过继承或引用适配者的对象,把适配者接口转换成目标接口,让客户按目标接口的格式访问适配者。
类适配器模式
对象适配器模式
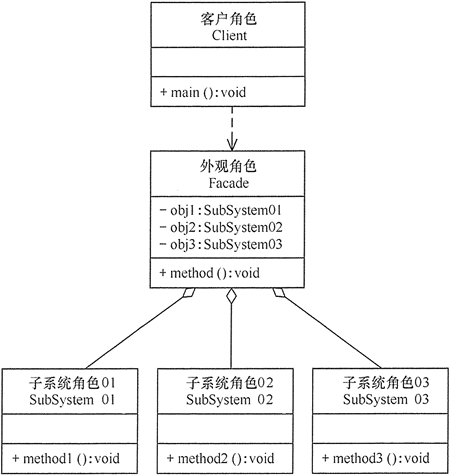
门面模式 定义 外观(Facade)模式的定义:是一种通过为多个复杂的子系统提供一个一致的接口,而使这些子系统更加容易被访问的模式。该模式对外有一个统一接口,外部应用程序不用关心内部子系统的具体的细节,这样会大大降低应用程序的复杂度,提高了程序的可维护性。
实现 主要角色
外观(Facade)角色:为多个子系统对外提供一个共同的接口。
子系统(Sub System)角色:实现系统的部分功能,客户可以通过外观角色访问它。
客户(Client)角色:通过一个外观角色访问各个子系统的功能。
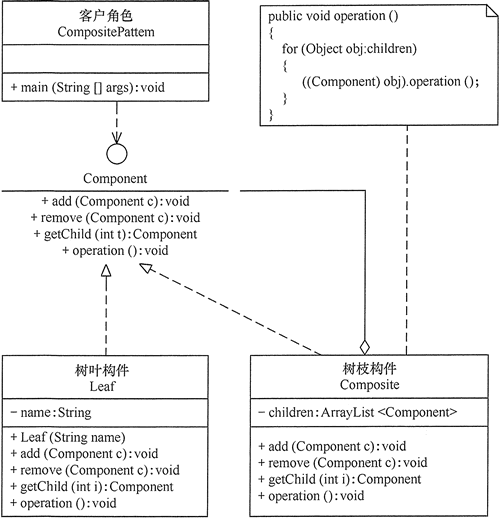
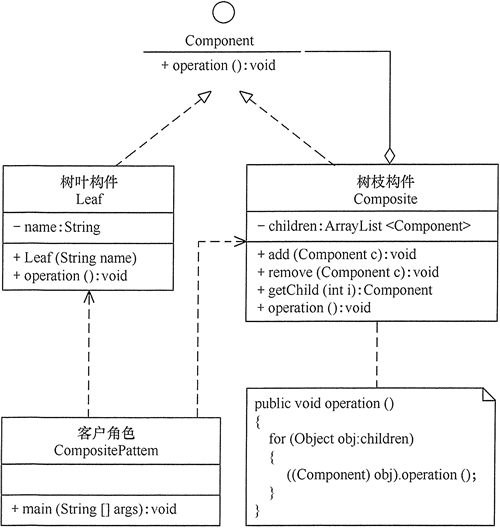
组合模式 定义 组合(Composite)模式的定义:有时又叫作部分-整体模式,它是一种将对象组合成树状的层次结构的模式,用来表示“部分-整体”的关系,使用户对单个对象和组合对象具有一致的访问性
实现 主要角色
抽象构件(Component):它的主要作用是为树叶构件和树枝构件声明公共接口,并实现它们的默认行为。在透明式的组合模式中抽象构件还声明访问和管理子类的接口;在安全式的组合模式中不声明访问和管理子类的接口,管理工作由树枝构件完成。
树叶构件(Leaf):是组合中的叶节点对象,它没有子节点,用于实现抽象构件角色中 声明的公共接口。
树枝构件(Composite):是组合中的分支节点对象,它有子节点。它实现了抽象构件角色中声明的接口,它的主要作用是存储和管理子部件,通常包含 Add()、Remove()、GetChild() 等方法。
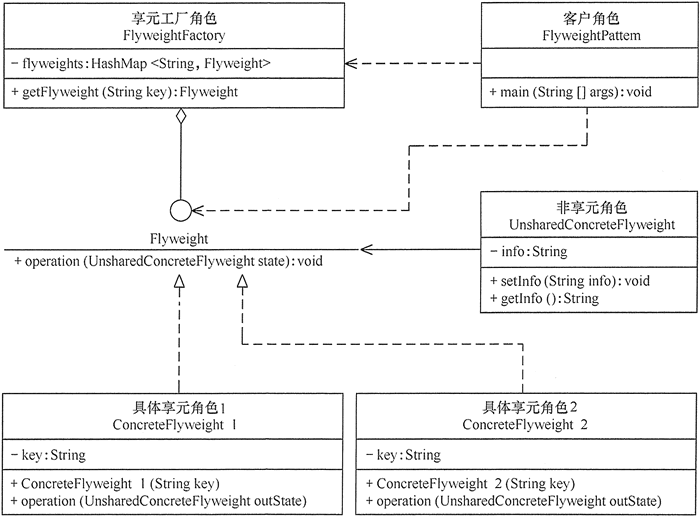
亨元模式 定义 享元(Flyweight)模式的定义:运用共享技术来有効地支持大量细粒度对象的复用。它通过共享已经存在的又橡来大幅度减少需要创建的对象数量、避免大量相似类的开销,从而提高系统资源的利用率。
实现 主要角色
抽象享元(Flyweight):是所有的具体享元类的基类,为具体享元规范需要实现的公共接口,非享元的外部状态以参数的形式通过方法传入。
具体享元(Concrete Flyweight):实现抽象享元角色中所规定的接口。
非享元(Unsharable Flyweight):是不可以共享的外部状态,它以参数的形式注入具体享元的相关方法中。
享元工厂(Flyweight Factory):负责创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检査系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。
行为型 模板方法 定义 模板方法(Template Method)模式 :定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
父类中定义公共方法或者执行步骤,有差异的部分由具体的子类去实现。
适用场景:
算法的整体步骤很固定,但其中个别部分易变时,这时候可以使用模板方法模式,将容易变的部分抽象出来,供子类实现。
当多个子类存在公共的行为时,可以将其提取出来并集中到一个公共父类中以避免代码重复。首先,要识别现有代码中的不同之处,并且将不同之处分离为新的操作。最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。
实现 主要角色
抽象类(Abstract Class)
模板方法:定义了算法的骨架,按某种顺序调用其包含的基本方法。
基本方法
抽象方法:在抽象类中申明,由具体子类实现。
具体方法:在抽象类中已经实现,在具体子类中可以继承或重写它。
钩子方法(非必须)在抽象类中已经实现,包括用于判断的逻辑方法和需要子类重写的空方法两种。
具体子类(ConcreteClass):实现抽象类中所定义的抽象方法和钩子方法
实现demo代码
为了避免子类较多,可以考虑匿名内部类,JedisCluster的命令实现就是一个很好的例子。
开源demo案例 JedisClusterCommand的实现即是一个明显的例子。JedisClusterCommand实现了分槽,获取connect,执行命令,重试等公共操作。子类中实现具体的执行命令。
JedisClusterCommand
JedisCluster.set
观察者模式 定义 观察者(Observer)模式: 指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式、模型-视图模式。
实现 主要角色
Subject 就是抽象主题:它负责管理所有观察者的引用,同时定义主要的事件操作。
ConcreteSubject 具体主题:它实现了抽象主题的所有定义的接口,当自己发生变化时,会通知所有观察者。
Observer 观察者:监听主题发生变化相应的操作接口。
Concrete Observer 具体观察者,实现抽象观察者中定义的抽象方法
实现demo代码
开源demo案例 命令模式 定义 命令(Command)模式 :将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行储存、传递、调用、增加与管理。
适合场景 :
当系统需要将++请求调用者与请求接收者解耦++时,命令模式使得调用者和接收者不直接交互。
当系统需要++随机请求命令或经常增加或删除命令++时,命令模式比较方便实现这些功能。
当系统需要++执行一组操作++时,命令模式可以定义宏命令来实现该功能。
当系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作时,可以将命令对象存储起来,采用备忘录模式来实现。
实现 主要角色 :
Command 命令:命令接口定义一个抽象方法
ConcreteCommand:具体命令,负责调用接受者的相应操作
Invoker 请求者:负责调用命令对象执行请求
Receiver 接受者:负责具体实施和执行一次请求
实现demo代码
开源demo案例 Tomcat 中命令模式在 Connector 和 Container 组件之间有体现,Tomcat 作为一个应用服务器,无疑会接受到很多请求,如何分配和执行这些请求是必须的功能。
Connector和Container两个接口。Connector是抽象命令请求者,Container是抽象命令接收者,server是这一切的缘由,HttpProcessor是抽象命令。
在tomcat中的实现形式是:server需要Connector来接受来自外接的Http请求,然后Connector接受到请求,并创建了命令HttpProcessor,然后server将这个命令交给了Container接收者。
参考
图说设计模式 设计模式